CrewAI是一款专为构建多智能体协作系统设计的开源框架,核心目标是通过模拟人类团队的分工协作模式,让多个 AI 智能体(Agent)以角色化、流程化的方式完成复杂任务。CrewAI 的出现重新定义了 AI 开发者的工作方式——从编写代码转向编排智能体团队。无论是构建企业级自动化系统,还是探索前沿的多智能体协作研究,CrewAI 都提供了强大且灵活的技术底座。
Ocean Protocol 是一个基于区块链的去中心化数据交换协议,旨在通过安全、透明的方式连接数据提供者与消费者,实现数据资产的自由流通与价值释放。其核心目标是构建一个无需中心化中介的「数据经济」,让数据所有者能够直接控制并货币化自己的数据,同时为开发者和企业提供开放的 AI 训练、研究及分析资源。
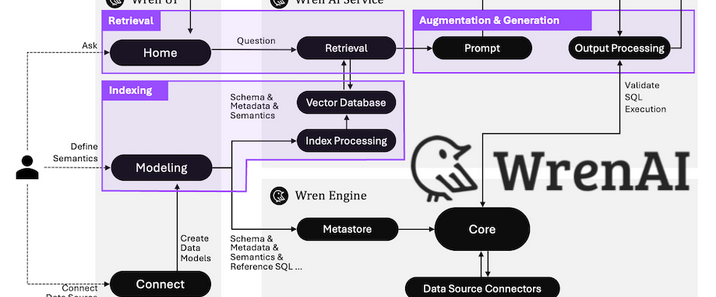
生成式 BI 工具支持自然语言查询数据库,自动生成 SQL 与可视化图表,被金融分析师和数据科学家广泛采用。WrenAI是由Canner团队开发的开源生成式BI(GenBI)智能体,致力于通过自然语言交互实现数据库查询、可视化生成和洞察报告的全流程自动化。其核心设计理念是语义层驱动的精准查询,通过预定义数据模型、业务指标和表关系,构建LLM可理解的“数据库说明书”,解决传统Text-to-SQL工具因缺乏上下文导致的高错误率问题。
VLM-R1是由浙江大学滨江研究院Om AI Lab开源的多模态视觉推理模型,聚焦复杂场景理解与自主推理路径构建,通过强化学习与视觉语言模型的深度融合,在多模态任务中展现出突破性能力。项目地址:https://github.com/om-ai-lab/VLM-R1一、技术架构VLM-R1采用视觉-语言-强化学习三层异构融合架构,实现多模态信息的深度交互与推理路径的自主生成: