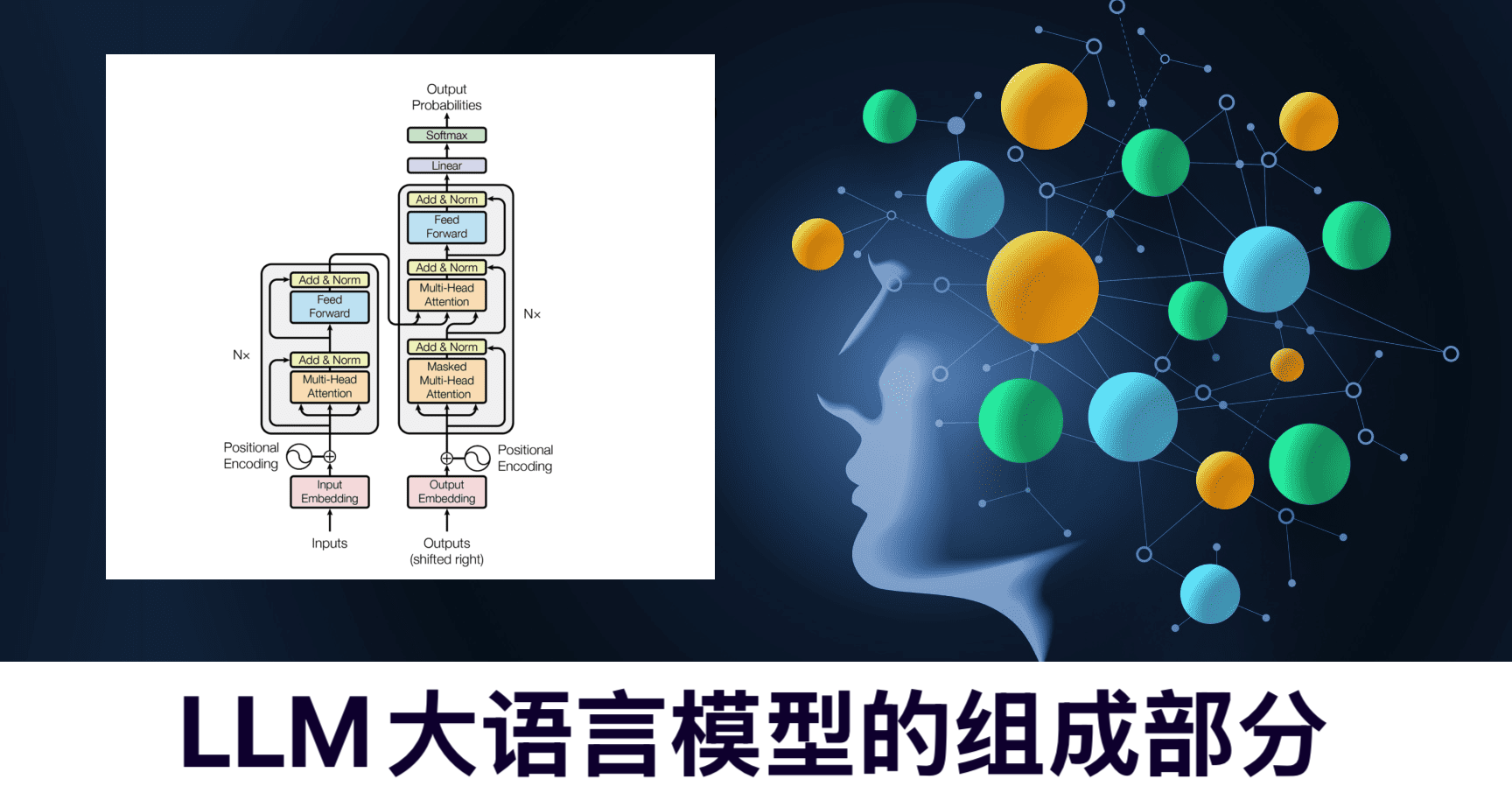
LLM(Large Language Model)大语言模型由输入层将文本转为向量,基于Transformer架构的编码器提取语义与上下文信息,解码器据此生成输出,输出层经Softmax和搜索策略将向量转为最终文本;通过在大规模无监督语料上预训练学习通用知识,再针对具体任务用有标注数据微调;记忆与缓存机制处理长序列并提高效率,评估模块用困惑度等指标衡量性能,优化模块据此调整超参数、改进结构 。
一、组成部分
1.输入层
- 功能:负责接收用户输入的文本数据,将原始的文本信息转化为模型能够处理的向量表示形式,即进行词嵌入等操作,把单词或句子映射到低维向量空间,以便后续的计算和处理。
- 常用技术:词袋模型、Word2Vec、GloVe等词嵌入技术,以及更先进的基于Transformer的字节对编码(Byte-Pair Encoding,BPE)等子词嵌入方法。
2.编码器
- 功能:对输入的向量序列进行编码,提取文本中的语义信息和上下文信息,将文本的各种特征进行抽象和表示,形成一个包含丰富语义的向量表示,为后续的语言生成等任务提供基础。
- 常用架构:Transformer编码器架构,它通过自注意力机制(Self-Attention)和前馈神经网络(Feed-Forward Neural Network)来对输入序列进行并行计算和特征提取,能够有效地捕捉文本中的长序列依赖关系;此外,也有一些模型采用递归神经网络(RNN)或长短期记忆网络(LSTM)等作为编码器。
3.解码器
- 功能:根据编码器提取的特征以及之前生成的文本信息,逐步生成下一个单词或字符等输出,通过预测下一个可能的词汇或标记,不断地构建出完整的文本内容,实现语言生成、问答等任务。
- 常用架构:同样以Transformer解码器架构为主流,它在生成过程中利用自注意力机制和交叉注意力机制(Cross-Attention)来融合编码器的输出和当前的生成状态,以生成合理的文本;在一些早期或特定的模型中,也会使用基于RNN或LSTM的解码器。
4.输出层
- 功能:将解码器生成的向量表示转换为最终的文本输出,通常是通过对预测的词汇分布进行采样或选择,得到具体的单词、句子或段落等文本内容,并展示给用户。
- 常用技术:Softmax函数用于计算词汇表中每个单词的概率分布,然后根据概率进行采样或选择,如贪心搜索、束搜索(Beam Search)等策略来确定最终的输出结果。
5.预训练与微调模块
- 预训练
- 功能:在大规模的无监督语料上进行预训练,学习语言的通用知识和模式,如语言的语法规则、语义理解、逻辑关系等,使模型能够具备一定的语言理解和生成能力。
- 常用方法:基于掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)等任务的自监督学习方法,以及基于因果语言模型(Causal Language Model,CLM)的自回归学习方法。
- 微调
- 功能:在预训练的基础上,针对具体的下游任务,如文本分类、情感分析、机器翻译等,使用相应的有标注数据对模型进行微调,进一步优化模型在特定任务上的性能,使模型能够更好地适应具体任务的需求。
- 常用方法:根据具体任务设计相应的损失函数和优化算法,对模型的参数进行微调,如在文本分类任务中使用交叉熵损失函数,在序列标注任务中使用条件随机场(CRF)损失函数等。
6.记忆与缓存机制
- 功能:帮助模型更好地处理长序列文本和提高生成效率。记忆机制可以存储模型在处理文本过程中的中间结果和关键信息,以便在后续的计算中快速访问和利用;缓存机制则用于缓存已经计算过的结果,避免重复计算,提高模型的推理速度。
- 常用技术:在Transformer架构中,多头注意力机制中的键值对(Key-Value)可以看作是一种简单的记忆结构,用于存储和查询文本中的信息;此外,一些模型还会使用外部的记忆模块或缓存策略,如基于哈希表的缓存、基于时间序列的缓存等。
7.评估与优化模块
- 评估
- 功能:用于衡量模型在训练和测试过程中的性能表现,通过各种评估指标来量化模型的语言理解和生成能力,如困惑度(Perplexity)、BLEU(用于机器翻译等生成任务)、准确率、召回率、F1值等,帮助开发者了解模型的优缺点,为模型的改进提供依据。
- 常用指标和方法:对于语言生成任务,常用的指标有BLEU、ROUGE等;对于文本分类等任务,常用准确率、召回率、F1值等指标;通过在测试数据集上进行评估,计算模型的各项指标得分,与基准模型或其他先进模型进行对比。
- 优化
- 功能:根据评估结果对模型进行优化和调整,包括调整模型的超参数,如学习率、层数、神经元数量等,以及改进模型的结构和算法,以提高模型的性能和效率。
- 常用方法:随机搜索、网格搜索、模拟退火算法、遗传算法等超参数优化方法,以及对模型结构进行改进,如增加层数、改进注意力机制、引入新的激活函数等。
二、高效协同
LLM大语言模型依赖各个组成部分高效协同。
1. 输入层与编码器协同
- 输入层将文本转化为向量后,有序地输入到编码器。编码器的自注意力机制会并行计算输入向量间的依赖关系,捕捉文本长序列信息,位置编码还会为输入向量添加位置信息,让编码器能识别文本顺序,使编码器对输入文本进行深度特征提取,为后续处理打好基础。
2. 编码器与解码器协同
- 在语言生成等任务中,编码器把提取到的包含丰富语义的向量表示传递给解码器。解码器中的交叉注意力机制会将编码器的输出与自身的自注意力机制输出进行融合,以此为基础预测下一个单词或字符的概率分布,生成与输入文本语义连贯的内容。
3. 解码器与输出层协同
- 解码器生成的是关于词汇的概率分布向量,输出层通过Softmax函数将其转换为可理解的文本。比如采用贪心搜索或束搜索等策略,依据概率分布选择最可能的单词作为输出,使生成的文本符合语言逻辑和表达习惯。
4. 预训练与微调模块和其他部分协同
- 预训练时,各层在大规模无监督语料上学习语言的通用模式和知识,调整自身参数。微调阶段,根据具体任务的有标注数据,各层在预训练基础上进一步优化,使输入、编码、解码和输出过程更适配特定任务需求。
5. 记忆与缓存机制和其他部分协同
- 记忆机制可存储编码器和解码器处理过程中的中间结果,便于后续生成时快速调用相关信息。缓存机制则对已计算结果进行缓存,在输入类似文本或重复计算某些内容时,直接获取缓存结果,减少计算量,提高各部分运行效率。
6. 评估与优化模块和其他部分协同
- 评估模块通过各种指标对模型输出进行评估,若发现模型在语言理解或生成方面存在问题,优化模块会调整各部分的超参数,如编码器和解码器的层数、神经元数量等,或改进结构,使各组成部分协同工作更高效,提升模型整体性能。
三、算法
1.注意力机制相关算法
- 自注意力机制(Self-Attention):让模型在处理文本序列时,能并行计算每个位置与其他位置的关联程度,确定当前位置的重要性权重,捕捉文本长序列中的依赖关系。例如在生成一句话时,能根据句子中其他词来确定当前词的重要性,更好地理解和生成语义。
- 多头注意力机制(Multi-Head Attention):由多个头的自注意力机制并行组成,每个头能捕捉不同角度的语义信息,然后将这些信息融合,丰富模型对文本的理解和表达能力。
2.神经网络相关算法
- Transformer架构:作为LLM的基础架构,核心是编码器和解码器堆叠,都由多头注意力机制和前馈神经网络组成,具有并行计算能力和出色的长序列处理能力,使模型能高效处理大规模文本数据。
- 多层感知机(MLP):常作为Transformer中的前馈神经网络部分,对注意力机制输出的特征进行进一步的非线性变换,增强模型的拟合能力,将低维特征映射到高维空间,挖掘更复杂的语义关系。
3.优化算法
- 随机梯度下降(SGD):及其变体Adagrad、Adadelta、RMSProp、Adam等,用于更新模型参数,通过计算损失函数关于参数的梯度,沿着负梯度方向更新参数,使模型在训练过程中逐渐收敛到最优解,以最小化损失函数。
- 学习率调整策略:如余弦退火(Cosine Annealing)、指数衰减(Exponential Decay)等,在训练过程中动态调整学习率,使模型在训练初期能快速收敛,后期能更精细地调整参数,避免错过最优解或陷入局部最优。
4.生成算法
- 贪心搜索(Greedy Search):在生成文本时,每一步都选择概率最高的单词作为输出,简单快速,但可能导致生成文本单一、缺乏多样性。
- 束搜索(Beam Search):在每一步生成时,同时保留多个概率较高的候选单词及其生成路径,综合考虑多个路径的得分来选择最优路径,能生成更符合语义、更具多样性的文本。
- 采样算法:包括多项式采样(Multinomial Sampling)等,根据模型输出的概率分布进行采样来生成单词,可引入随机性,使生成结果更丰富多样,但可能会产生一些不符合语法或语义的文本,通常会结合温度参数等进行调整。
5.其他算法
- 位置编码(Positional Encoding):由于Transformer架构本身不具有对文本位置信息的感知能力,位置编码算法将位置信息融入输入向量,使模型能识别文本的顺序,如正弦位置编码(Sinusoidal Positional Encoding)通过正弦和余弦函数为不同位置的输入添加独特的位置特征。
- 层归一化(Layer Normalization):对神经网络每层的输入进行归一化处理,加速模型收敛,减少梯度消失或爆炸问题,提高模型的稳定性和泛化能力。