DeepSeek应用稀疏动态架构(Sparse Dynamic Architecture)是其大模型技术的核心创新点。大模型稀疏动态架构是一种用于构建大规模人工智能模型的先进架构,整体提高了模型的效率、灵活性和性能。
一、发展历程
1.早期探索阶段
起源基础:20世纪8090年代的早期机器学习主要集中在决策树、SVM、KNN等经典算法,模型规模小,依赖手工特征。之后在2006年Geoffrey Hinton提出逐层无监督预训练缓解深层网络训练难题,为深度学习发展奠定基础。
稀疏概念初现:早期的神经网络中,就有研究尝试通过一些简单的方法来实现稀疏性,如L1正则化等,鼓励模型的参数变得稀疏,以减少过拟合和模型复杂度,但这一阶段的稀疏性应用相对较为初级,还没有形成完整的稀疏动态架构概念。
2.深度学习崛起与初步应用阶段
深度学习崛起:2012年AlexNet在ImageNet竞赛的成果,标志着深度学习大规模应用开始。
稀疏架构初步尝试:随着深度学习的发展,一些研究开始探索更复杂的稀疏架构,如稀疏自动编码器等,尝试通过自动学习的方式来发现数据中的稀疏表示。在自然语言处理领域,一些基于循环神经网络(RNN)和长短时记忆网络(LSTM)的模型也开始尝试引入稀疏连接或动态调整机制,以提高模型对长序列数据的处理能力。
3.Transformer架构推动阶段
Transformer架构提出:2017年谷歌提出Transformer模型框架,随后基于Transformer的BERT、GPT2等模型推动自然语言处理发展。
稀疏动态架构发展:以稀疏混合专家(MoE)架构为代表的稀疏动态架构开始出现并应用于Transformer架构中,如谷歌的GShard和Switch Transformer,通过将一个大型神经网络分解为多个“专家”网络,每个专家网络专门处理特定类型的输入,提高了模型的效率和性能。
4.大模型时代的深化与拓展阶段
大模型爆发:2020年后,超大规模语言模型如GPT4、PaLM、Claude等以及多模态模型Clip、DALLE等发展迅猛。
架构持续创新:大模型稀疏动态架构不断创新和优化,出现了更先进的稀疏注意力机制、动态路由算法和可调节模块设计。例如SepLLM聚焦于关键标记类型实现稀疏注意力机制,ChineseMixtral采用稀疏混合专家架构并在多个评测基准上表现优异。
应用领域拓展:大模型稀疏动态架构在自然语言处理、计算机视觉、语音识别等多个领域得到了广泛的应用和拓展,推动了人工智能技术在各个领域的发展和落地。
二、关键组成部分
1.稀疏连接:传统的神经网络通常具有密集的连接,即每个神经元与大量的其他神经元相连。而在大模型稀疏动态架构中,采用了稀疏连接的方式,只有一部分神经元之间存在连接。这样可以大大减少模型的参数数量和计算量,同时也有助于减少模型的过拟合风险,提高模型的泛化能力。
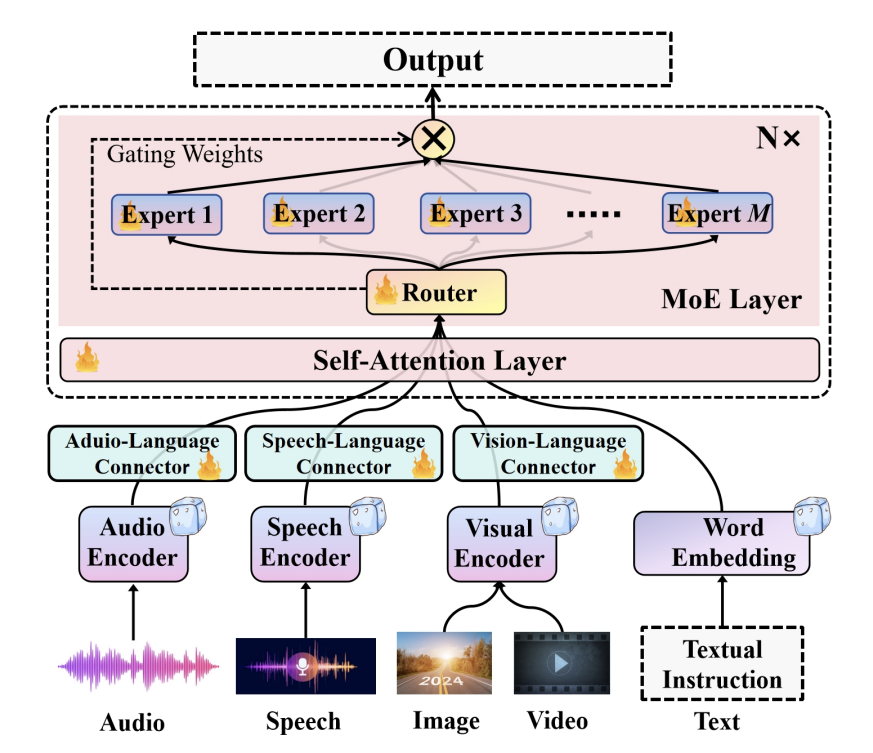
2.稀疏MoE层
多专家结构:稀疏MoE层由多个“专家”构成,每个专家本质上是一个独立的神经网络,通常是简单的前馈网络,也可采用更复杂结构甚至嵌套MoE层,形成多层次专家体系。每个专家FFN结构比传统FFN更简单,因为单个专家只需处理特定类型输入。
稀疏激活策略:在每次前向传播中,仅部分专家会被激活并参与计算。不是所有专家都会同时使用,每个token只会路由到最相关的专家,这使得模型在保持高维特征空间中表达复杂模式的同时,显著降低了计算开销。专家之间相互独立,可以并行计算,提高了计算效率。
3..动态路由机制:该架构引入了动态路由机制,能够根据输入数据的特点,动态地决定数据在模型中的传播路径。也就是说,不同的输入数据会根据其特征被路由到不同的子网络或神经元集合中进行处理,使得模型能够更高效地处理各种不同类型的数据,提高模型的适应性和灵活性。
4.门控网络/路由机制
动态分配功能:门控网络负责动态分配输入token到特定的专家,根据输入特征选择最适合处理这些特征的专家,有时一个token甚至可被分配到多个专家以提高鲁棒性。
实现方式:依赖由参数化学习驱动的路由器,通常是小型神经网络或逻辑模块,输出一组概率或分配权重指引令牌分发过程。路由器参数与主模型共同优化,能在不同训练阶段动态适应数据分布和任务需求。
工作流程:首先计算路由概率,用于选择FFN专家,然后生成一个门控值,这个门控值会与选中的FFN专家的输出相乘,最终输出为选中的FFN专家的输出与门控值的乘积。门控值用于调节FFN专家输出的强度,可看作对专家输出的加权因子,能实现更平滑的输出。
5.可调节的模块:包含一些可调节的模块,这些模块的参数或结构可以根据训练过程中的数据和任务需求进行动态调整。例如,在训练过程中,模型可以根据数据的分布变化,自动调整某些模块的权重或激活函数,以更好地适应数据的特点,从而提高模型的性能。
三、特点及优势
1.高效性:通过稀疏连接和动态路由,大模型稀疏动态架构能够在保证模型性能的前提下,显著减少计算量和存储需求,提高模型的训练和推理速度,使其能够更高效地处理大规模的数据和复杂的任务。
2.灵活性:动态调整的特性使模型能够根据不同的任务和数据分布,自动优化自身的结构和参数,具有很强的灵活性和适应性。这意味着同一个模型可以在多种不同的应用场景中表现出色,无需为每个特定任务重新设计和训练模型。
3.泛化能力强:稀疏连接和动态调整有助于模型学习到更具一般性的特征,避免过拟合,从而提高模型在未知数据上的泛化能力,使其在各种实际应用中都能具有更稳定和可靠的性能。
4.降低计算成本:通过稀疏激活机制,只让部分专家参与计算,避免了传统稠密模型中大量不必要的计算,在保证模型性能的前提下,大幅减少了计算量,降低了训练成本。
5.提高模型效率:动态路由机制使模型能根据输入自动分配到最合适的专家进行处理,提高了模型处理不同类型数据的效率和针对性,有助于提升模型的整体性能和泛化能力。
四、现状和趋势
1.研究现状
理论基础研究深入:研究发现大模型普遍存在稀疏激活现象,即大量神经元激活值对输出贡献小。如早期的稀疏混合专家模型利用此特性,强制每个词仅用部分专家计算。此外,神经元功能定位也有进展,发现了知识、技能、语言等功能神经元。
架构创新不断涌现:清华等团队提出可配置基础模型(CFM),将大模型分为预训练涌现模块和后训练定制模块。通过模块的检索、组合、更新、增长实现复杂功能配置与组合。还有ProSparse方法,可将大语言模型转化为更高稀疏度的ReLU激活版本,缓解下游任务性能损失。
应用场景逐渐拓展:在自然语言处理任务中表现出色,能像处理复杂指令、生成文本等。可复用性和可扩展性使其在不同领域应用时,能快速调整模块适应需求。分布式计算特性也使其在端云协同等场景有应用优势,如将隐私数据模块部署在端侧,通用模块部署在云端。
仍面临一些挑战:主流大模型采用的GELU、SiLU等激活函数缺乏显式稀疏激活特性,给稀疏化带来困难。如何平衡模型稀疏度和性能是研究重点,既要提高稀疏度降低计算成本,又要保证任务表现不下降。
2.未来发展趋势
技术优化方向
更高的稀疏度与性能平衡:研究将进一步探索模型稀疏度和正则化约束等的定量关系,实现更高稀疏度同时,确保模型性能不降低甚至提升,挖掘更优的激活函数或优化现有函数以满足稀疏化需求。
与其他技术融合:与量化、蒸馏等模型压缩技术结合,进一步降低存储和计算成本。融合多模态技术,处理图像、语音等多模态数据时,利用稀疏动态架构提高效率。
应用拓展方向
端侧应用普及:随着架构优化和硬件发展,稀疏动态架构大模型将更易于部署在终端设备,如手机、智能家居等,实现本地化智能处理,减少对云端的依赖,提高响应速度和数据安全性。
跨领域深度应用:在医疗、金融、教育等更多复杂领域,根据领域特点和任务需求,定制化配置模型模块,提供精准智能服务,如医疗领域辅助诊断、金融领域风险预测等。
模型架构演进方向
更灵活的模块化设计:模块的划分和组合将更灵活智能,根据输入和任务自动调整模块结构和连接方式,实现自适应的模型计算。
向类脑智能靠近:借鉴人脑的稀疏动态特性,进一步挖掘大模型的类脑智能潜力,提高模型的学习、推理和泛化能力,使其更接近人类的智能水平。
五、应用案例
1.SepLLM
原理:聚焦于初始标记、邻近标记以及分隔标记这三种关键标记类型,利用这些标记对段落信息进行压缩,削减计算开销,同时保留关键上下文,实现了稀疏注意力机制。
应用成果:能够轻松应对超过400万个标记的序列,在GSM8KCOT基准测试中,将KV缓存使用量锐减了50%,与采用Llama38B架构的标准模型相比,计算成本降低了28%,训练时间缩短了26%。在GSM8KCOT和MMLU基准测试中,在将KV缓存使用量削减至47%的情况下,性能仍能与全注意力模型相媲美。
2.ChineseMixtral
原理:采用稀疏混合专家(Sparse Mixture of Experts,MoE)架构,在每个前馈网络(FFN)层包含多个“专家”子网络,推理时根据输入动态选择最相关的专家子网络计算,保持较小计算量的同时实现更大模型容量。
应用成果:开发了Chinese Mixtral基础模型和Chinese Mixtral Instruct指令微调模型,在CEval、CMMLU、MMLU、LongBench等评测基准上表现优异,支持32K tokens的上下文窗口,实测可达128K,在长文本处理、数学推理、代码生成等方面能力出色。
3.PanguΣ
原理:采用稀疏架构,使用ECSS机制提高训练系统的效率和可伸缩性。
应用成果:可用于对话、翻译、代码生成和自然语言解释等多个下游应用,在中文领域的16个下游任务中大幅超越了之前的SOTA模型。
4.BigBird
原理:采用“稀疏自注意力”技术,引入block sparse、global和random attention等不同的稀疏模式,并结合Zoom Attention局部细化关注技术。
应用成果:能将时间复杂度降低到O(NlogN)或更低,可处理长达数万甚至数十万个token的序列,适用于长篇文档理解、机器翻译、对话系统、知识图谱构建与问答等场景,在处理长文本时能保持更好的上下文连贯性,在连续多轮对话中能更好地记住对话历史,在理解大量背景知识的问题时能更好地捕获相关信息。
5.makeMoE
原理:利用稀疏混合专家层,并引入Topk门控和噪声Topk门控机制,通过对最活跃的专家节点进行选择,减少计算负担。
应用成果:可以生成莎士比亚式的文本,可应用于文本生成、深度学习教育、大规模模型实验等场景,能够创作文学作品、新闻报道或对话,也可用于自动摘要和文本翻译。