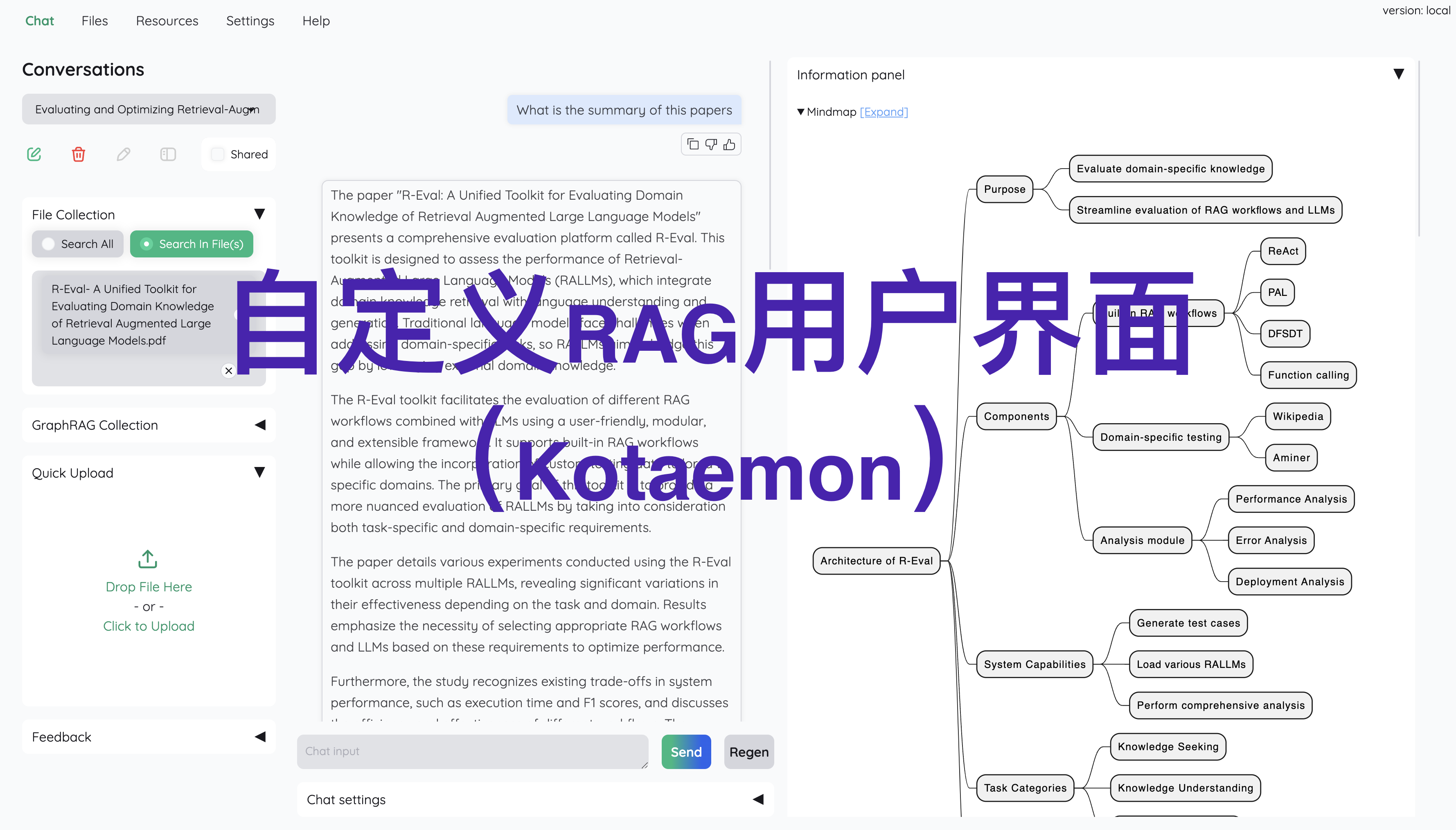
kotaemon由Cinnamon开发开源,提供了一个干净且自定义的RAG用户界面,通过与文档的聊天功能,帮助用户进行问答。兼容多种LLM API供应商,包括OpenAI、Azure OpenAI和Cohere,以及本地模型。支持多用户登录,允许用户将文件组织成公共或私有集合并进行共享,能够处理包括图形和表格在内的多种文档格式,支持多模式文件解析。适用于需要进行文档问答的终端用户,以及希望构建自己的RAG管道的开发者。
项目地址:https://github.com/Cinnamon/kotaemon
一、核心功能
1.简洁可定制UI:基于Gradio框架构建,界面简洁直观,用户可在深色和浅色模式间切换。开发者能自由定制或添加UI元素,还可选择和定制不同主题。
2.多用户支持与协作:支持多用户登录,用户可将文件组织成公共或私有集合并进行共享,还能分享聊天对话,促进协作和知识共享。
3.丰富模型支持:兼容多种LLM API供应商,如OpenAI、Azure OpenAI和Cohere,也支持本地模型。
4.混合RAG管道:默认采用混合的全文本检索和向量检索,并提供重新排名机制,确保最佳检索质量,向用户呈现最相关信息。
5.多模态QA功能:能够处理包含图形、表格等多种模态的文档,将多模式元素融入QA流程。
6.高级引文功能:系统自动提供详细的引用信息,可在浏览器的PDF查看器中查看引用及相关分数,确保LLM答案的正确性,还设有警告系统,对低相关性结果进行提醒。
7.复杂推理支持:提供多跳QA的问题分解功能,还实现了ReACT、ReWOO等基于代理的推理框架,能对复杂问题做出更动态、更情境感知的响应,此外还包括对GraphRAG索引的实验性支持。
8.可配置设置界面:用户可在UI上调整检索和生成过程中的重要参数,如提示等,使系统更符合个人需求。
二、安装方式
1.使用Docker
- 拉取镜像:执行`docker run -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-lite`命令,拉取并运行Kotaemon的Docker镜像,其中main-lite为精简版本,还有full版本支持更丰富文件类型但镜像较大。
2.不使用Docker
- 创建并激活环境:首先创建名为kotaemon的Python3.10环境并激活,执行`conda create -n kotaemon python=3.10`和`conda activate kotaemon`。
- 克隆项目:使用`git clone https://github.com/Cinnamon/kotaemon`命令克隆项目代码到本地,并进入项目目录。
- 安装依赖:运行`pip install -e \"libs/kotaemon(all)\"`安装项目所需依赖。
3.配置
- 模型连接和凭据配置:在`.env`文件中配置模型连接和凭据,支持OpenAI、Azure OpenAI等多种LLM提供商以及通过Ollama或llama - cpp - python的本地模型。
- 应用程序高级配置:通过`flowsettings.py`文件进行高级配置,如设置文档存储、向量存储以及启用或禁用特定功能。
4.启动与访问
- 启动:安装并配置完成后,在项目目录下执行`python app.py`启动应用程序。
- 访问:在浏览器中输入`http://localhost:7860`,即可打开Kotaemon界面进行使用。
5.基本使用步骤
- 添加AI模型:在界面中找到模型设置选项,选择所需的LLM API提供商或本地模型,并进行相应的配置,如输入API密钥等。
- 文件上传:点击文件上传按钮,选择需要进行问答的文档,支持多种格式。
- 与文档聊天:在聊天输入框中输入问题,系统会根据上传的文档和所选模型进行回答。
- 查看信息面板:查看系统提供的相关信息,如引用、检索结果评分等,以了解答案的来源和可靠性。
三、应用场景
1.学术科研
- 文献综述与研究:研究人员可以利用Kotaemon快速检索大量学术文献,对相关领域的研究成果进行梳理和总结,辅助撰写文献综述。
- 课题探索与创新:在探索新课题时,通过Kotaemon与学术知识交互,获取不同角度的观点和研究思路,激发创新想法,为研究课题提供方向和灵感。
- 学术交流与讨论:在学术会议或小组讨论中,Kotaemon可作为知识共享和交流的工具,帮助参与者快速查找和引用相关文献,支持观点阐述和讨论深入。
2.法律事务
- 案例检索与分析:律师在处理案件时,能够使用Kotaemon检索类似案例,分析法律条款的应用和判决结果,为当前案件提供参考依据,制定合理的辩护策略。
- 法规查询与解读:法律工作者可以借助该界面快速查询法律法规,获取准确的法律条文内容,并通过其分析和解读功能,更好地理解法律条款的含义和适用范围。
- 法律文件审查:在审查合同、法律文件等工作中,Kotaemon可以帮助快速检索相关法律规定和以往案例,检查文件是否存在法律风险和漏洞。
3.技术支持
- 故障排查与解决:技术支持人员在面对用户反馈的问题时,可通过Kotaemon检索技术文档、常见问题解答库等,快速找到问题的解决方案,提高故障排查效率。
- 产品使用指导:为用户提供产品使用方面的帮助,当用户遇到操作问题时,Kotaemon能根据用户输入的问题,检索出相应的操作指南和教程,指导用户正确使用产品。
- 技术知识分享:在技术团队内部,Kotaemon可作为知识分享平台,团队成员可以分享技术经验、解决方案等,方便其他成员在遇到类似问题时进行检索和学习。
4.客户服务
- 常见问题解答:企业客服人员使用Kotaemon快速查找常见问题的答案,及时回复客户咨询,提高客户满意度。
- 个性化服务推荐:根据客户的需求和历史记录,Kotaemon可以检索相关的产品或服务信息,为客户提供个性化的推荐和解决方案。
- 客户投诉处理:在处理客户投诉时,通过Kotaemon检索类似投诉案例和处理经验,为投诉处理提供参考,确保问题得到妥善解决。
5.医疗健康
- 临床决策支持:医生在诊断和治疗过程中,可利用Kotaemon检索最新的医学研究成果、临床指南和病例数据,为临床决策提供参考依据,提高诊断准确性和治疗效果。
- 患者健康管理:医疗机构可以通过Kotaemon为患者提供健康知识查询服务,帮助患者了解疾病预防、治疗和康复等方面的知识,提高患者的自我健康管理能力。
- 医学教育与培训:在医学教育中,Kotaemon可作为教学工具,帮助医学生快速检索医学知识,辅助学习和研究,同时也可用于医学培训中的案例分析和讨论。
6.金融投资
- 市场分析与预测:金融分析师可以使用Kotaemon检索金融市场数据、行业报告、经济新闻等信息,进行市场趋势分析和预测,为投资决策提供支持。
- 投资产品推荐:根据客户的投资需求、风险偏好等信息,Kotaemon能够检索合适的投资产品信息,为客户提供个性化的投资产品推荐。
- 风险评估与管理:在进行投资风险评估时,通过Kotaemon检索相关的风险案例和数据,分析潜在风险因素,制定有效的风险控制策略。
四、其他类似工具
1.LangChain
- 功能特性:文档加载器可从数据库、API和本地文件等获取数据,支持PDF、文本文件等多种格式;通过模板化结构创建动态提示,根据检索数据定制提示;能与Chroma、Pinecone等向量数据库集成以实现内存管理,维持交互中的上下文。
- 应用场景:适用于开发各种基于大型语言模型的应用,如智能聊天机器人、智能文档分析系统等,帮助快速构建起具有复杂交互功能和强大数据处理能力的应用程序。
2.LlamaIndex
- 功能特性:提供树形、列表、向量存储、关键词表等多种索引方式,适用于不同类型和规模的数据;可将嵌入模型与向量数据库的检索器相结合,以最小延迟高效检索相关数据,支持从多种文件、API、数据库等加载数据。
- 应用场景:在处理大规模数据集的检索和生成任务时表现出色,如企业级的知识管理系统、学术研究数据检索平台等,能为用户快速准确地提供相关知识和信息。
3.Haystack
- 功能特性:支持Elasticsearch、FAISS等多种文档存储后端;具有检索-阅读器流水线,包含FARMReader、TransformersReader等多种阅读器,还可通过OpenAI GPT-3/4进行生成模型;提供用于评估QA和搜索流水线的内置工具。
- 应用场景:主要用于构建搜索和问答系统,在智能客服、知识检索平台等领域应用广泛,能为用户提供准确、全面的答案和搜索结果。
4.Verba
- 功能特性:有简洁易用的用户界面,便于用户操作;可灵活选择嵌入模型,支持与多种LLMs集成,如Llama、OpenAI、Anthropic等;具备混合搜索能力,支持PDF、HTML等多种文档类型。
- 应用场景:可用于快速搭建各种RAG应用,尤其是对用户界面要求较高、需要与多种模型和文档类型交互的场景,如企业内部的知识查询系统、智能文档处理平台等。
5.Unstructured
- 功能特性:专注于统一和转换不同数据格式,以适配向量数据库和LLM框架;支持多种文件类型和20多种数据源,基于文档模型进行元素转换和优化。
- 应用场景:在数据预处理和整合方面具有优势,适用于需要处理大量不同格式数据的场景,如数据中台、企业数据仓库等,为后续的RAG应用提供高质量的数据支持。
6.Neum
- 功能特性:强调源、连接器和终点等清晰定义,关注大规模数据摄取问题,支持语义分块;提供无代码管线构建器和清晰语法的Pipeline配置。
- 应用场景:适用于需要处理大规模数据的RAG应用场景,如大型企业的数据分析平台、数据密集型的科研项目等,帮助用户快速构建数据处理和生成的管线。