强化学习从人类反馈(Reinforcement Learning from Human Feedback,RLHF)是一种将人类反馈融入机器学习模型训练的技术。通过将人类的偏好、评价或直接指导等反馈作为奖励信号,训练奖励模型,再利用该奖励模型通过强化学习来优化智能体的策略,使智能体的行为与人类期望和偏好保持一致。
传统强化学习依赖预先定义的奖励函数来指导智能体行为优化,但对于许多实际问题,设计准确反映目标并激励正确行为的奖励函数很困难。尤其在涉及复杂人类价值或审美判断的任务中,人类直觉更有效,因此产生了RLHF方法。
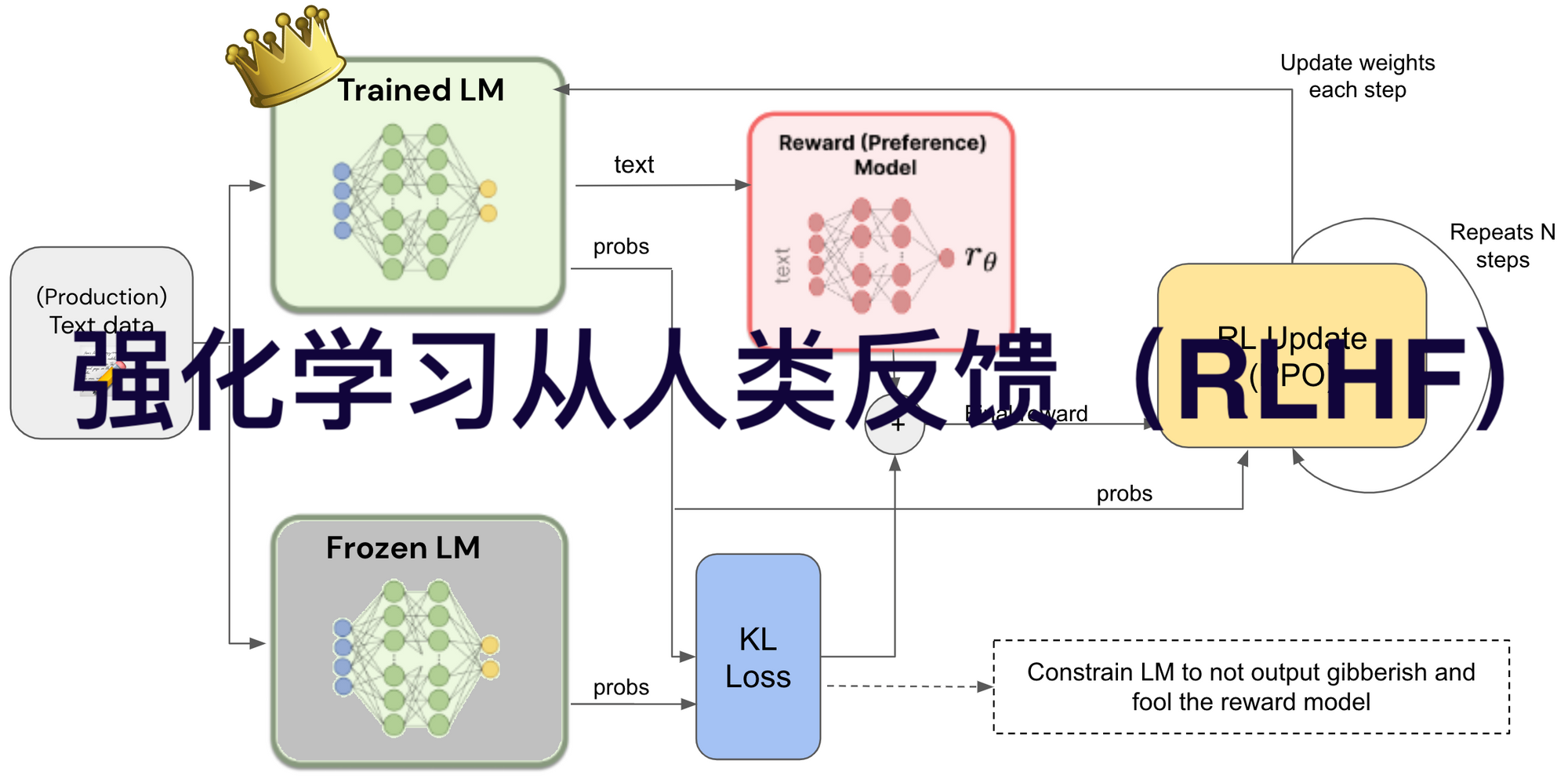
一、基本流程
1.收集人类反馈:通常让人类对智能体的行为实例进行排序,也有研究探索使用数值反馈、自然语言反馈或直接对模型输出进行编辑等形式。比如在训练文本生成模型时,让人类对生成的文本进行打分或排序。
2.训练奖励模型:利用收集到的人类反馈数据,以监督学习的方式训练奖励模型,使其能预测给定提示下的响应是好(高奖励)还是坏(低奖励)。
3.策略优化:使用强化学习算法,如近端策略优化算法(PPO),结合奖励模型来优化智能体的策略,让智能体学习生成能获得高奖励的输出。
二、主要步骤
强化学习从人类反馈(RLHF)的具体工作流程一般包括收集人类反馈数据、训练奖励模型、基于奖励模型进行策略优化以及评估与迭代这几个主要步骤。
1.收集人类反馈数据
确定反馈任务和场景:明确需要人类提供反馈的具体任务和应用场景,例如在对话系统中,可能是对聊天机器人的回复进行评价;在图像生成中,可能是对生成图像的质量和风格进行判断。
选择反馈主体:挑选合适的人类标注者或用户群体来提供反馈。这些人需要具备与任务相关的知识或经验,能够做出合理的判断。
设计反馈收集方式:常见的方式有对模型输出进行打分、排序,或者直接指出问题和提出改进建议等。比如在文本生成任务中,让标注者对生成的文本按照质量从高到低进行排序,或者给出010分的评分。
收集反馈数据:将模型生成的样本或执行的操作展示给人类反馈提供者,收集他们的反馈信息,形成反馈数据集。
2.训练奖励模型
特征提取:对输入数据(如对话的上下文、生成的文本、图像的特征等)和模型输出进行特征提取,将其转换为适合模型处理的向量表示。
构建奖励模型架构:通常采用神经网络架构,如Transformer、卷积神经网络(CNN)等,根据任务的特点选择合适的模型结构。例如在自然语言处理任务中,常使用基于Transformer的模型。
使用反馈数据训练模型:以人类反馈作为监督信号,采用监督学习的方法训练奖励模型。将收集到的反馈数据分为训练集、验证集和测试集,使用训练集对奖励模型进行训练,通过调整模型的参数,使得模型能够准确地预测人类反馈的得分或偏好。在训练过程中,使用损失函数(如均方误差损失、交叉熵损失等)来衡量模型预测结果与真实反馈之间的差异,并通过优化算法(如随机梯度下降、Adam等)来最小化损失函数,从而更新模型参数。
3.基于奖励模型进行策略优化
选择强化学习算法:常用的算法有近端策略优化算法(PPO)、深度Q网络(DQN)及其变体等。这些算法用于在给定奖励模型的情况下,优化智能体的策略。
策略网络初始化:构建策略网络,其参数通常是随机初始化的。策略网络用于生成智能体的行为策略,例如在对话系统中,策略网络根据当前的对话状态生成回复文本。
与环境交互并收集轨迹:智能体根据当前的策略网络在环境中进行交互,生成一系列的行为轨迹。在每个时间步,智能体根据策略网络输出的概率分布选择一个动作,并观察环境返回的新状态和奖励信号。这里的奖励信号由奖励模型根据智能体的行为和环境状态来计算。
更新策略网络:根据收集到的行为轨迹和奖励信号,使用强化学习算法对策略网络进行更新。算法通过最大化累计奖励来调整策略网络的参数,使得智能体能够学习到更优的策略,以获得更高的奖励。
4.评估与迭代
模型评估:使用独立的测试数据集对优化后的模型进行评估,评估指标可以根据具体任务而定,如在文本生成中可以使用BLEU、ROUGE等指标,在图像生成中可以使用图像质量评估指标(如PSNR、SSIM等)。同时,也可以通过人工评估的方式,让人类对模型的输出进行主观评价,判断模型是否达到预期的效果。
迭代优化:根据评估结果,对整个RLHF流程进行调整和优化。如果模型性能不满足要求,可以收集更多的人类反馈数据,调整奖励模型的结构或训练参数,或者选择更合适的强化学习算法和超参数,然后重复上述步骤,不断改进模型。
三、优势和挑战
1.优势
提高模型性能:使模型生成的结果更符合人类需求和偏好,提高模型在具体任务上的准确性、相关性和质量,如让语言模型生成更自然、合理的文本。
增强模型适应性:帮助模型更好地处理复杂、难以明确定义目标的任务,能适应不同场景下人类的多样化需求和偏好。
提升模型可解释性:人类反馈为模型训练提供了更直观的指导,一定程度上使模型的决策过程和输出结果更易于理解。
2.挑战
数据收集成本高:获取高质量的人类反馈数据需要耗费大量的人力、时间和资源。
数据偏差问题:如果反馈数据的收集样本不具有代表性,可能导致模型产生偏差,不能很好地泛化到其他情况。
人类反馈的主观性和不一致性:不同人对同一事物的评价和偏好可能存在差异,同一人在不同时间的反馈也可能不一致,这给模型训练带来一定困难。
四、应用领域
1.自然语言处理领域
对话系统:使聊天机器人能够根据人类对对话内容的满意度反馈,学习生成更符合用户期望、更有针对性和亲和力的回复,提升用户体验,让对话更加自然流畅。
文本生成:在创作故事、诗歌、新闻等文本内容时,根据人类对生成文本的质量、风格、主题相关性等方面的反馈,优化模型,生成更优质、更符合特定要求的文本。
文本摘要:帮助模型根据人类对摘要的准确性、完整性、简洁性等评价,学习生成更理想的文本摘要,提取出最关键和有用的信息。
2.智能决策领域
机器人控制:人类可以根据机器人完成任务的情况,如动作的准确性、效率、灵活性等给予反馈,机器人通过RLHF学习调整策略,更好地完成如物品搬运、环境探索、任务协作等工作。
自动驾驶:根据人类驾驶员对自动驾驶系统在行驶过程中的安全性、舒适性、决策合理性等方面的反馈,优化自动驾驶模型,使车辆的驾驶策略更接近人类的驾驶习惯和期望,提高自动驾驶的可靠性和用户接受度。
资源管理与调度:在云计算资源分配、物流运输调度、能源管理等场景中,依据人类对资源利用效率、任务完成时间、成本等方面的反馈,优化调度算法,实现更高效的资源配置和任务安排。
3.推荐系统领域
个性化推荐:根据用户对推荐内容(如商品、新闻、音乐、视频等)的点击、浏览、购买等行为反馈,以及对推荐结果的满意度评价,模型通过RLHF不断调整推荐策略,为用户提供更个性化、更符合其兴趣和需求的推荐内容,提高用户对推荐系统的信任度和使用频率。
推荐排序:利用人类对推荐列表中不同项目顺序的偏好反馈,优化推荐结果的排序,将用户更感兴趣的内容排在更靠前的位置,提升用户发现感兴趣内容的效率。
4.游戏领域
游戏AI优化:在游戏开发中,让游戏AI根据玩家对游戏难度、AI行为策略的反馈,通过RLHF调整自身的行为模式和决策逻辑,为玩家提供更具挑战性和趣味性的游戏体验。
游戏内容生成:根据玩家对游戏关卡、剧情、角色等内容的反馈,利用RLHF优化游戏内容生成模型,创造出更受玩家喜爱的游戏元素和情节。
5.图像与多媒体领域
图像生成与编辑:根据人类对生成图像的质量、风格、内容准确性等方面的反馈,优化图像生成模型,使其生成更符合人类审美和需求的图像,也可用于图像编辑任务,根据用户反馈实现更精准的图像修改。
视频内容创作:在视频生成、视频剪辑等任务中,依据人类对视频的情节、节奏、画面效果等的反馈,通过RLHF技术优化模型,创作出更吸引人的视频内容。