基于强化学习(Reinforcement Learning)的自主思考模型通过纯强化学习训练模型,让AI能够自己去发现问题的解决方案,避开了传统数据集依赖带来的“脆弱性”,使AI模型能够更加自主地推理和解决问题,提高了模型的泛化能力和适应性。
它能够通过与环境进行交互,不断学习和优化自己的行为策略,以实现特定的目标。
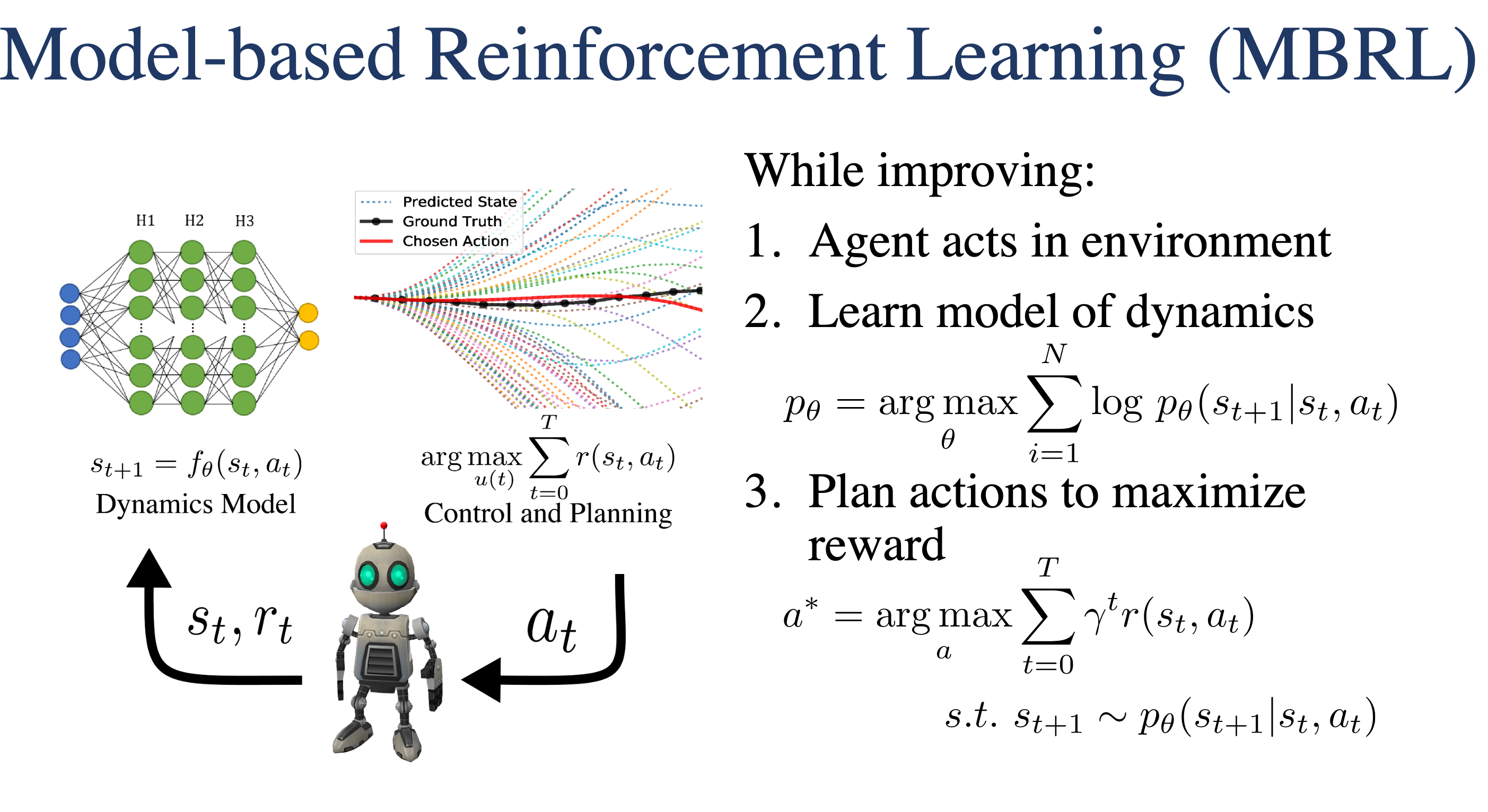
一、基本原理
1.环境与智能体:模型中存在一个智能体和它所处的环境。智能体可以在环境中执行各种动作,环境会根据智能体的动作反馈给它一个奖励信号和新的状态。例如,在一个机器人导航任务中,机器人是智能体,它所处的房间和周围的障碍物等构成了环境。
2.策略网络:智能体通过策略网络来决定在当前状态下应该采取什么动作。策略网络通常是一个神经网络,它以环境的状态作为输入,输出每个可能动作的概率或价值。比如,在玩游戏的智能体中,策略网络根据游戏当前画面(状态)输出是选择向左移动、向右移动还是开火等动作的概率。
3.奖励机制:环境会根据智能体的动作给予相应的奖励。奖励是智能体学习的动力,它旨在引导智能体采取有利于实现目标的动作。例如,在棋类游戏中,赢得比赛可能会得到+1的奖励,输掉比赛得到1的奖励,而在游戏过程中的一些有利局面可能会得到较小的正奖励。
4.学习过程:智能体通过不断地与环境交互,收集状态、动作和奖励等信息,来更新策略网络,以最大化长期累积奖励。这个过程类似于人类通过不断尝试和犯错来学习如何更好地完成任务。
二、关键要素
1.探索与利用:智能体需要在探索新的动作和利用已知的有效动作之间进行平衡。探索有助于发现更好的策略,但可能会暂时导致奖励降低;利用则是基于已有的经验选择看起来最优的动作。例如,一个智能体在探索一个新的地图时,需要不断尝试新的路径(探索),同时也会利用已经发现的较短路径(利用)。
2.价值函数:用于评估智能体在某个状态下的长期价值。它可以帮助智能体判断当前状态的好坏,以及预测采取某个动作后未来可能获得的奖励。常见的价值函数包括状态价值函数和动作价值函数,如深度Q网络(DQN)中的Q函数。
3.模型更新算法:如深度强化学习中常用的深度Q网络(DQN)及其扩展算法,利用神经网络来逼近价值函数或策略函数,并通过反向传播算法来更新网络参数。此外,还有基于策略梯度的算法,如A2C、A3C、PPO等,直接对策略网络进行优化。
三、优势
1.自主学习能力:基于强化学习的自主思考模型能够通过与环境的交互,不断试错并学习最优的行为策略,无需人为详细地规定每一步的操作。例如在游戏中,智能体可以从一无所知开始,逐渐摸索出最佳的游戏策略,这大大减少了人工编程的工作量,使模型具有更强的自主性和灵活性。
2.环境适应性:该模型可以根据环境反馈的奖励信号,动态调整自己的行为,以适应不断变化的环境条件。比如在机器人导航任务中,当环境中的障碍物布局发生改变时,机器人能够通过强化学习重新学习路径规划,找到新的最优路径。
3.处理复杂决策问题:可以处理具有多个决策步骤和长期目标的复杂问题,通过考虑长期累积奖励来做出决策。以金融投资为例,模型能够综合考虑市场的各种因素和长期的收益情况,制定出合理的投资策略。
4.与深度学习结合的潜力:强化学习可以与深度学习相结合,形成深度强化学习,利用深度学习强大的特征提取能力,处理高维、复杂的感知数据。如在图像识别与决策任务中,先利用深度学习对图像进行特征提取,再由强化学习根据这些特征做出决策,这使得模型能够处理更复杂、更真实世界的问题。
5.涌现出创新行为:在学习过程中,模型可能会发现一些人类难以事先设计或预料到的新行为和策略,从而为解决问题提供新的思路和方法。比如在一些复杂的资源管理问题中,模型可能会找到一种全新的资源分配方式,提高整体效率。
四、挑战
1.样本效率低:强化学习通常需要大量的样本数据和时间来学习到有效的策略,学习过程可能非常缓慢,尤其是在复杂环境中。例如在训练一个能够在复杂城市环境中自动驾驶的模型时,需要让车辆进行大量的实际行驶或模拟行驶才能获得足够的学习数据,这不仅耗时,还可能存在安全风险。
2.收敛问题:模型的训练过程可能不稳定,难以保证收敛到最优策略,甚至可能会陷入局部最优解。特别是在具有高维状态空间和动作空间的环境中,这个问题更为突出。比如在一些复杂的博弈游戏中,智能体可能会陷入一种看似不错但并非全局最优的策略。
3.奖励函数设计困难:合理的奖励函数对于引导智能体学习到期望的行为至关重要,但设计一个准确、有效的奖励函数往往非常困难。如果奖励函数设计不当,可能会导致智能体学习到错误的行为策略。例如在设计一个用于训练机器人进行垃圾分类的强化学习模型时,如何准确地定义奖励来鼓励正确分类、惩罚错误分类,同时考虑到不同垃圾的价值和处理难度等因素,是一个复杂的问题。
4.探索与利用平衡难题:智能体需要在探索新的动作和利用已知的有效动作之间找到平衡。在实际应用中,很难确定一个通用的、适用于各种环境的探索与利用策略。如果探索过多,会导致学习效率低下;如果利用过多,又可能错过更好的策略。
5.对环境的依赖性强:模型的性能高度依赖于环境的稳定性和可预测性。如果环境变化过于剧烈或存在不可预测的因素,模型可能无法很好地适应,导致性能下降。例如在一些实时的网络通信环境中,网络延迟、带宽变化等不可预测因素可能会影响基于强化学习的网络资源分配模型的性能。
6.可解释性差:与一些传统的机器学习模型相比,强化学习模型的决策过程和行为模式往往难以理解和解释。智能体为什么选择某个动作,以及它是如何学习到当前策略的,很难直观地进行解释,这在一些对可解释性要求较高的应用场景中,如医疗、金融监管等领域,可能会限制其应用。
五、应用领域
1. 机器人领域
运动控制:机器人可以通过强化学习不断调整关节角度、步伐等参数,学会在不同地形如崎岖山路、冰雪路面等环境中行走、跳跃、攀爬,像波士顿动力的机器人就大量运用了强化学习技术来实现复杂动作。
任务操作:在工业生产中,机械臂利用强化学习能学会精准抓取、装配零件;在家庭服务场景下,机器人可学习完成如收拾餐具、整理衣物等任务。
2. 交通领域
自动驾驶:车辆通过强化学习与周围交通环境交互,学习在不同路况、天气和交通信号下的最佳驾驶策略,如合理控制车速、安全变道、高效超车等。
交通调度:可以对交通信号灯进行智能控制,根据实时车流量调整绿灯时长,优化交通流;还能用于出租车、共享单车等的智能调度,提高资源利用率。
3. 能源领域
电网调度:智能电网系统利用强化学习模型,根据不同地区的电力需求、发电情况等,优化电力分配和调度,降低传输损耗,提高电网运行效率和稳定性。
能源管理:在智能建筑中,通过强化学习可根据室内外环境、用户需求等因素,自动调节空调、照明等设备的运行,实现节能减排。
4. 医疗领域
医疗机器人:手术机器人可以借助强化学习技术学习更精准的手术操作动作,提高手术的成功率和安全性;康复机器人能根据患者的康复情况调整训练方案和力度。
医疗决策辅助:医生可参考强化学习模型根据患者的病历、症状等信息给出的治疗方案建议,结合临床经验做出更科学的医疗决策,如制定肿瘤的化疗方案等。
5. 金融领域
投资决策:投资者可以利用强化学习模型分析金融市场数据,综合考虑风险和收益,学习最佳的投资组合策略和交易时机,实现资产的增值。
风险管理:金融机构通过强化学习模型评估信用风险、市场风险等,根据风险状况调整信贷政策、资产配置等,提高风险管理能力。
6. 游戏领域
游戏AI:游戏中的虚拟角色可以通过强化学习学会更智能的行为,如在格斗游戏中学会不同的攻击和防御策略,在即时战略游戏中学会合理的资源管理和战术安排。
游戏设计:开发者利用强化学习来优化游戏关卡设计和难度调整,根据玩家的游戏行为和反馈,自动生成更具挑战性和趣味性的游戏内容。
7. 通信领域
网络资源分配:通信系统中的基站等设备可以通过强化学习,根据用户数量、数据流量等动态分配频谱、带宽等资源,提高网络通信质量和效率。
路由选择:在网络路由中,强化学习模型可根据网络拓扑结构、链路状态等信息,学习最优的路由策略,减少数据传输延迟和丢包率。