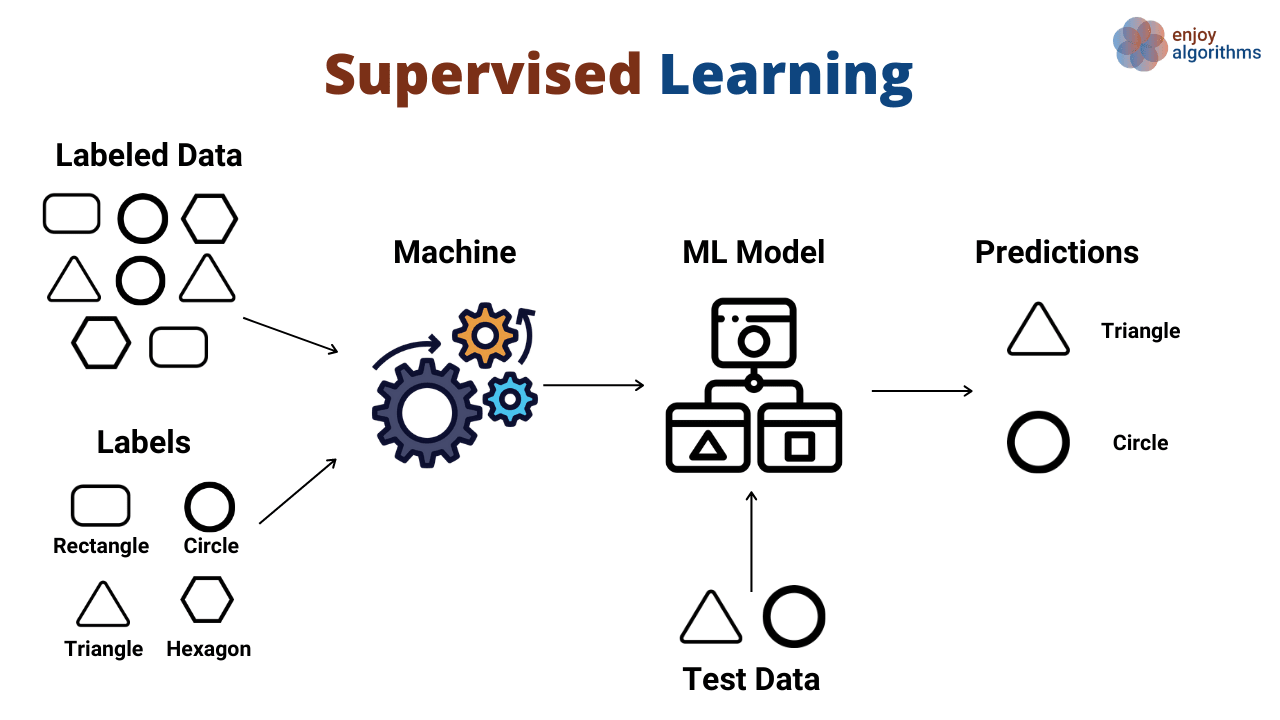
人工智能有监督学习(Supervised Learning in Artificial Intelligence)是一种重要的机器学习方法,有监督学习是指利用标记好的训练数据来训练模型,让模型学习输入特征与输出标签之间的映射关系,从而能够对新的、未见过的数据进行预测和分类的机器学习技术。在有监督学习中,训练数据集中的每个样本都包含输入特征和对应的输出标签(也称为目标值或真实值),模型通过学习这些样本的特征和标签之间的关系,来构建一个能够对新数据进行准确预测的函数。
有监督学习常用于识别图像中的物体,如人脸识别、车牌识别等。通过大量标记好的图像数据训练模型,让模型学习不同物体的特征,从而能够对新的图像进行准确识别。
在语音识别领域,将语音信号转换为文字,如语音助手、语音输入法等。模型通过学习大量的语音样本及其对应的文字内容,来实现对新语音的准确识别和转换。
在自然语言处理领域如文本分类、情感分析、机器翻译等。例如在文本分类中,通过标记好的文本数据训练模型,让模型学习不同类别文本的特征,从而对新的文本进行分类。
一、发展阶段
有监督学习大致可分为以下几个重要阶段:
1.早期理论奠基(20世纪5060年代)
1950年,阿兰·图灵发表了《计算机器与智能》的论文,提出了著名的图灵测试,为判断机器是否具有智能提供了一种思路,也为人工智能的发展奠定了理论基础。
1957年,罗森布拉特提出了感知机模型,这是一种最简单的有监督学习神经网络模型,能够对线性可分的数据进行分类,标志着有监督学习在神经网络领域的初步探索。
2.挫折与低谷(20世纪6080年代)
由于当时计算机性能有限,以及理论和技术的局限性,感知机等简单模型在面对复杂问题时表现不佳,如无法解决异或问题等。
1969年,明斯基和帕伯特在《感知机》一书中对感知机进行了深入分析,指出了其局限性,导致人工智能研究进入了第一次低谷期,有监督学习的发展也受到了一定的阻碍。
3.重新崛起与发展(20世纪8090年代)
1986年,鲁梅尔哈特等人提出了反向传播算法(BP算法),解决了多层神经网络的训练问题,使得有监督学习在神经网络领域取得了重大突破,能够处理更复杂的非线性问题,推动了人工智能的第二次发展浪潮。
这一时期,决策树、支持向量机等有监督学习算法也得到了深入研究和发展。决策树算法如ID3、C4.5等,能够根据数据的特征进行分类和决策,具有可解释性强的特点;支持向量机则在小样本、非线性分类问题上表现出色,成为了有监督学习领域的重要算法之一。
4.快速发展与广泛应用(21世纪初2010年代)
随着计算机硬件技术的飞速发展,特别是图形处理单元(GPU)在计算中的应用,极大地提高了模型的训练速度,使得大规模数据的有监督学习成为可能。
深度学习算法在有监督学习中取得了巨大成功,如深度神经网络(DNN)、卷积神经网络(CNN)、循环神经网络(RNN)及其变体长短时记忆网络(LSTM)、门控循环单元(GRU)等。这些算法在图像识别、语音识别、自然语言处理等领域取得了突破性的成果,推动了人工智能技术在工业、医疗、交通、金融等多个领域的广泛应用。
5.深度融合与创新(2010年代至今)
有监督学习与无监督学习、强化学习等其他学习方式相互融合,形成了更强大的人工智能模型和算法,如生成对抗网络(GAN)结合了有监督学习和无监督学习的思想,能够生成逼真的图像、文本等数据。
预训练模型成为有监督学习的重要发展方向,如BERT、GPT等大规模预训练语言模型,在自然语言处理任务中取得了惊人的效果。这些模型通过在大规模无监督数据上进行预训练,然后在有监督的下游任务上进行微调,大大提高了模型的性能和泛化能力。
二、关键步骤
1. 数据收集
确定数据来源:从各种渠道收集数据,如传感器采集、网络爬取、数据库获取、人工标注等。例如在图像识别任务中,可从公开图像数据集下载图片,或自行拍摄并标注图像。
确保数据多样性:为使模型具有良好的泛化能力,数据应涵盖各种可能的情况和特征,如在预测疾病的任务中,要收集不同年龄段、性别、地域等患者的数据。
2. 数据预处理
数据清洗:去除数据中的噪声、错误数据和重复数据,如删除包含乱码或明显错误标注的样本。
数据归一化/标准化:将数据的特征值缩放到特定范围或转化为特定分布,如将图像像素值归一化到01区间,或对数值特征进行标准化,使其均值为0,方差为1。
数据编码:将非数值型数据转换为数值型数据,如将文本标签“苹果”“香蕉”“橙子”编码为[0, 1, 2],或使用独热编码表示。
3. 模型选择与构建
根据任务选择模型:根据具体的应用场景和数据特点选择合适的模型架构,如分类任务可选决策树、支持向量机等,回归任务可选线性回归、多项式回归等。
确定模型超参数:超参数是在模型训练前需要手动设置的参数,如神经网络的层数、神经元个数、学习率、迭代次数等。
4. 模型训练
划分数据集:将预处理后的数据划分为训练集、验证集和测试集,一般按照7:2:1或8:1:1的比例划分。训练集用于训练模型,验证集用于调整超参数和监控模型训练过程,测试集用于评估模型的最终性能。
选择损失函数:损失函数用于衡量模型预测结果与真实标签之间的差异,如分类任务常用交叉熵损失函数,回归任务常用均方误差损失函数。
优化算法:使用优化算法来最小化损失函数,如随机梯度下降(SGD)、Adagrad、Adadelta、Adam等。这些算法通过调整模型的参数来使损失函数的值逐渐减小。
训练模型:将训练数据输入到模型中,通过前向传播计算预测结果,然后根据损失函数计算损失值,再通过反向传播算法更新模型的参数,不断迭代这个过程,直到损失函数收敛或达到预设的迭代次数。
5. 模型评估
使用测试集评估:在测试集上运行训练好的模型,计算各种评估指标,如分类任务中的准确率、精确率、召回率、F1值,回归任务中的均方误差、平均绝对误差等。
模型比较与选择:如果尝试了多个不同的模型或不同的超参数组合,根据评估指标选择性能最优的模型。
分析评估结果:通过混淆矩阵、误差分析等方法,深入了解模型在不同类别或数据样本上的表现,找出模型的优点和不足,为模型改进提供依据。
6. 模型部署与应用
模型部署:将训练好的模型部署到实际的生产环境中,如将图像识别模型部署到安防监控系统中,或将文本分类模型部署到智能客服系统中。
实时预测与反馈:模型在实际运行中对新的未知数据进行预测,并根据预测结果提供相应的决策支持或服务。同时,收集实际应用中的新数据和反馈信息,用于进一步优化和更新模型。
三、与无监督学习等的区别
有监督学习:数据集中包含明确的输入特征和输出标签,模型的目标是学习输入到输出的映射关系,主要用于预测、分类等任务。
无监督学习:数据集中只有输入特征,没有给定的输出标签或目标值,模型的任务是发现数据中的模式、结构或规律,如聚类、降维等。
强化学习:智能体在环境中进行一系列的动作,通过与环境的交互获得奖励反馈,模型的目标是学习如何选择最优的动作序列以最大化长期奖励,常用于机器人控制、游戏等领域。
四、应用场景
1.工业制造
缺陷检测:利用有监督学习算法,通过大量标记好的正常与缺陷产品图像数据,训练图像识别模型。模型可以快速、准确地检测出生产线上产品的外观缺陷,如手机屏幕的划痕、汽车车身的凹陷等,提高产品质量检测的效率和准确性。
故障诊断:基于设备运行的各种参数数据,如温度、压力、振动等,以及对应的设备故障类型标签,训练故障诊断模型。当设备运行时,模型可以实时监测数据并预测设备是否存在故障以及故障的类型,提前进行维护,减少设备停机时间。
2.交通运输
自动驾驶:有监督学习在自动驾驶领域发挥着关键作用。通过收集大量的道路场景图像、车辆行驶数据以及相应的驾驶操作指令(如转向角度、刹车、加速等)作为训练数据,训练自动驾驶模型。使车辆能够识别交通标志、车道线、行人、其他车辆等,做出合理的驾驶决策。
交通流量预测:根据历史交通流量数据、时间、天气等因素以及对应的交通流量状态标签,训练预测模型。可以对不同时间段、不同路段的交通流量进行预测,为交通管理部门制定交通疏导策略、优化信号灯时长等提供依据。
3.教育领域
个性化学习:根据学生的学习行为数据、学习成绩等信息以及对应的学习阶段、知识掌握程度等标签,为每个学生建立个性化的学习模型。系统可以根据模型预测学生的学习需求,推送适合的学习资料和练习题,提高学习效果。
智能批改:利用有监督学习算法,通过大量的标准答案和学生作答样本进行训练,让模型学习如何对学生的作业和试卷进行批改和评分。不仅可以提高批改效率,还能对学生的答题情况进行分析,为教师提供教学反馈。
4.娱乐行业
内容推荐:视频、音乐、新闻等平台根据用户的历史浏览、收藏、点赞等行为数据以及对应的用户兴趣标签,训练推荐模型。为用户提供个性化的内容推荐,提高用户的参与度和平台的用户粘性。
游戏角色行为模拟:在游戏开发中,通过有监督学习训练游戏角色的行为模型。根据不同的游戏场景、玩家操作等输入以及对应的角色最佳行为策略标签,使游戏角色能够做出更加智能、合理的反应,提升游戏的趣味性和真实感。
5.农业领域
作物病虫害检测:通过拍摄大量带有病虫害症状的作物图像,并标记出病虫害的类型和严重程度,训练图像识别模型。可以帮助农民快速检测作物是否受到病虫害侵袭,及时采取防治措施,减少农作物损失。
产量预测:基于土壤数据、气象数据、种植管理数据以及对应的农作物产量数据,训练产量预测模型。帮助农民提前规划种植计划、合理安排资源,也为农产品市场预测和供应链管理提供参考。
6.医疗诊断:根据患者的症状、检查结果等数据,预测疾病类型或疾病的严重程度等。通过大量的病例数据训练模型,帮助医生进行辅助诊断。
7.金融风险预测:预测股票价格走势、信用风险评估、欺诈检测等。利用历史金融数据和对应的风险标签训练模型,为金融决策提供支持。