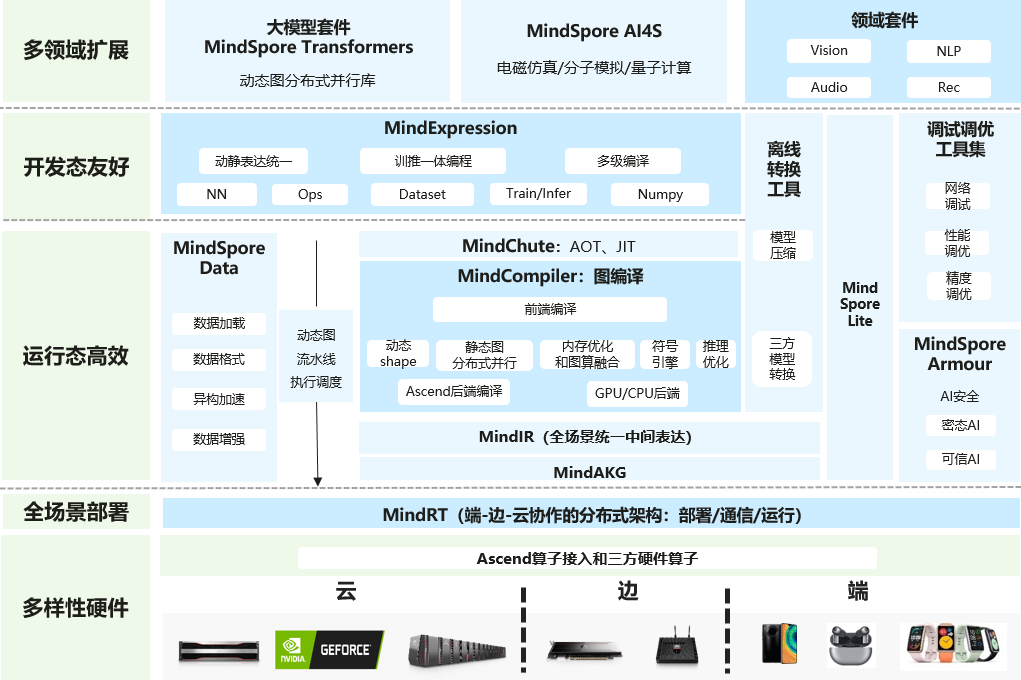
MindSpore是华为推出的一款全场景深度学习开源框架。旨在实现不同计算平台(如云端、边缘端、端侧)和不同硬件(如CPU、GPU、Ascend等)之间的高效协同。无论是在数据中心的大规模计算,还是在手机、物联网设备等资源受限的终端上,MindSpore都能灵活适配,充分发挥各硬件平台的性能优势,实现模型的高效训练和推理。
该框架引入了自动并行技术,能够根据模型结构和硬件资源自动进行并行策略的搜索和优化。这使得开发者无需手动进行复杂的并行计算配置,就能轻松实现模型的分布式训练,大大提高了开发效率和资源利用率。
MindSpore支持动态图和静态图两种编程方式。动态图模式下,代码的执行流程更加直观,方便开发者进行模型的调试和快速验证;静态图模式则具有更高的执行效率,适合大规模的模型训练和部署。开发者可以根据不同的需求灵活切换,充分发挥两种模式的优势。
官网地址:https://www.mindspore.cn
一、技术特性
1.高效的计算图优化:MindSpore具备强大的计算图优化能力,能够对模型的计算图进行自动优化,包括算子融合、内存复用等技术,减少计算量和内存开销,提高模型的训练和推理速度。
2.混合精度训练:支持混合精度训练,即在训练过程中同时使用单精度(FP32)和半精度(FP16)数据类型。半精度数据类型占用的内存更小,计算速度更快,通过混合精度训练可以在不显著降低模型精度的前提下,大幅提高训练效率。
3.端到端开发体验:提供了从数据处理、模型构建、训练到部署的全流程开发工具和接口,开发者可以在一个统一的环境中完成整个项目的开发,减少了不同工具之间的切换成本,提高了开发效率。
二、技术原理
1.计算图机制
构建计算图:MindSpore将深度学习模型的计算过程表示为计算图,图中的节点代表各种计算操作,如加法、乘法、卷积、池化等,边则表示数据的流动方向。在模型定义时,框架会根据用户编写的代码自动构建计算图,记录模型的计算逻辑和数据依赖关系。
计算图优化:为提高计算效率,MindSpore会对构建好的计算图进行优化。通过算子融合技术,将多个相邻的、可以合并的算子合并为一个算子,减少计算过程中的数据搬运和函数调用开销。还会进行内存复用优化,分析计算图中数据的生命周期,合理分配内存,使不同的数据在不同时间复用相同的内存空间,降低内存占用。
2.自动微分原理
正向传播和反向传播:在训练过程中,首先进行正向传播,数据按照计算图的定义依次通过各个算子进行计算,得到模型的输出结果。然后根据损失函数计算出损失值,接着进行反向传播,从损失函数开始,按照计算图的反向拓扑顺序,利用链式法则自动计算每个参数的梯度。
自动微分实现方式:MindSpore采用了源到源转换的自动微分技术,在计算图构建阶段,对原始的计算图进行转换,为每个需要求导的算子添加对应的反向传播算子,生成一个新的用于计算梯度的反向计算图。在反向传播过程中,根据这个反向计算图来计算梯度。
3.并行计算原理
数据并行:将训练数据分成多个子集,分别在不同的计算设备上进行计算。每个设备都有完整的模型副本,在正向传播和反向传播过程中,各个设备独立计算自己所负责的数据子集的梯度,然后通过通信机制将梯度进行汇总和平均,更新模型参数。
模型并行:当模型规模较大,无法在单个设备上完整存储和计算时,采用模型并行。将模型的不同部分分配到不同的设备上,每个设备负责计算模型的一部分。在计算过程中,设备之间需要进行数据通信,以保证模型的正确计算。
混合并行:结合数据并行和模型并行的优点,根据模型的特点和硬件资源情况,灵活地将数据并行和模型并行结合起来使用,以实现更高效的并行计算。MindSpore通过自动并行技术,能够根据模型结构和硬件资源自动搜索和生成最优的并行策略,无需用户手动进行复杂的配置。
4.分布式训练原理
通信机制:在分布式训练中,多个计算节点之间需要进行数据通信,以交换模型参数、梯度等信息。MindSpore采用了高效的通信库,如华为自研的Ascend Communication Library(ACL)等,实现节点之间的快速数据传输。
同步和异步训练:支持同步训练和异步训练两种模式。在同步训练中,所有节点在每个训练步骤都等待其他节点完成计算,然后进行梯度汇总和参数更新,保证所有节点的模型参数一致;异步训练中,节点可以独立进行计算和参数更新,不需要等待其他节点,提高了训练的并行度和效率,但可能会影响模型的收敛速度和精度,MindSpore会根据具体情况选择合适的训练模式。
5.内存管理原理
内存分配策略:根据模型的计算图和数据流动情况,MindSpore采用了基于静态分析和动态分配相结合的内存分配策略。在模型编译阶段,通过静态分析计算图中每个算子的输入输出数据形状和数据类型,估算出所需的内存空间,并进行初步的内存分配。在运行时,根据实际的数据大小和计算需求,进行动态的内存调整和分配。
内存回收机制:利用引用计数和垃圾回收技术来管理内存的回收。当一个数据对象不再被其他对象引用时,其引用计数为零,框架会自动回收该对象所占用的内存空间。同时,MindSpore还会定期进行垃圾回收,清理不再使用的内存对象,释放内存资源,避免内存泄漏和碎片问题。
三、优势
1.技术特性方面
自动并行能力突出:MindSpore能自动实现模型并行和数据并行等,一条语句即可完成自动并行设置。而像PyTorch等框架通常需要用户手动进行复杂的并行配置,这大大增加了开发的难度和工作量。
二阶优化优势明显:传统的深度学习框架多采用一阶优化算法,如梯度下降法等。MindSpore推出了二阶优化,能更快地找到损失函数的最优解,加速模型的收敛速度。
自动微分高效简洁:MindSpore内置了强大的自动微分机制,可自动生成反向传播的计算图,无需用户手动推导和编写求导代码。
计算图优化先进:采用图算融合技术,将算子与图层的表达进行统一,打破了原有算子和图层之间的信息边界,实现更通用、更细粒度的算子融合。
2.硬件适配方面
昇腾芯片深度协同:与华为的昇腾AI芯片深度适配和优化,能够充分发挥昇腾芯片的强大算力,在分布式训练和推理效率上表现出色。
多硬件平台支持:除了昇腾芯片,MindSpore还支持GPU、CPU等多种硬件平台。
3.易用性方面
API简洁直观:MindSpore的API设计简单易懂,代码逻辑更直观,新手上手更容易。
中文文档与社区支持:对于国内用户来说,MindSpore提供了丰富的中文文档和活跃的中文社区。
3.应用场景方面
全场景覆盖:明确提出端边云按需协同计算的理念,支持从云端到终端的一体化部署。
AI For Science领域领先:提出了“AI For Science”的概念,在科学计算领域有独特优势,比如在气象模拟、新药研发、蛋白质结构预测、流体力学计算等方面。
隐私保护能力强:提供了差分隐私训练模块等隐私保护技术,通过限制单个数据对数据分析结果的影响,防止反推个人敏感信息。
四、实际应用案例
1.图像语义分割:利用MindSpore可以实现基于FCN(全卷积网络)的图像语义分割任务,在自动驾驶中可用于识别道路、行人、车辆等;在医学影像分析里能对器官、肿瘤等进行分割;在安防监控中可对监控画面中的场景和目标进行精细分割,帮助实现更精准的目标检测与跟踪。
2.抗体设计:昌平实验室和协和医学院开发的基于MindSpore的抗体设计模型“天工”,通过多段功能区域的联合分布改造生成抗体序列,能够实现抗体功能设计、序列嫁接和活性预测等多种任务。相比传统抗体设计方法,“天工”模型设计效率提升一个数量级以上,有效缩短了抗体药物研发周期。
3.皮肤癌诊断:基于华为MindSpore开发的皮肤癌诊断项目,通过深度学习和图像识别技术,开发了智能诊断系统,利用移动端图像自动检测皮肤癌,解决了皮肤科医生短缺和早期诊断困难的问题。系统集成了InsightFace人脸识别技术,提高了诊断准确性,还使用Tkinter窗口技术,提升了用户界面友好性。
4.客户行为分析:某大型银行应用东方通的中间件与MindSpore AI框架进行客户行为分析,借助AI的智能预测,使客户满意度在短短几个月内提升了30%,提升了银行的风险管理、客户服务及精准营销的能力。
5.大模型训练:MindSpore凭借丰富的并行能力,支撑了国内多个领域首发大模型的训练,包括知识问答、知识检索、知识推理、阅读理解、文本/视觉/语音多模态、生物制药、遥感、代码生成等,涵盖20多个大模型训练,其中有6个千亿参数大模型,覆盖NLP、Audio、CV、多模态等领域。