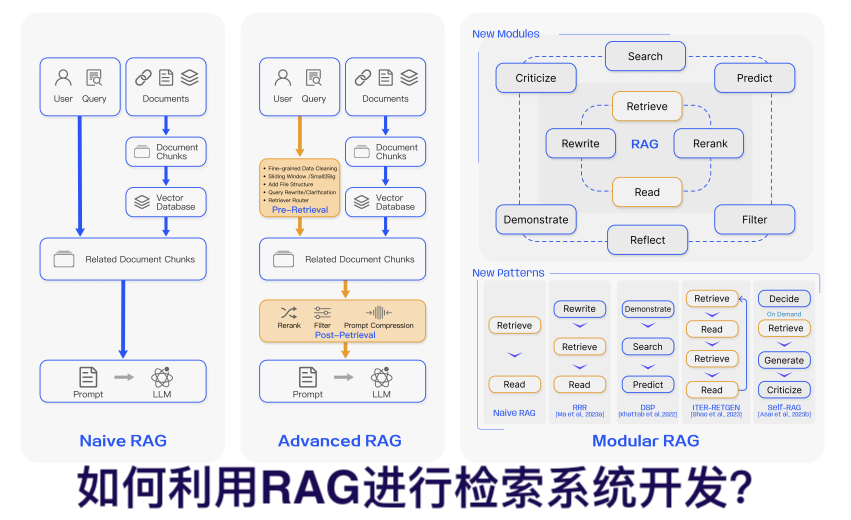
RAG(Retrieval Augmented Generation)检索增强生成是一种 AI 框架,它将传统信息检索系统(如搜索和数据库)的优势与生成式大型语言模型 (LLM ) 的功能相结合。通过将您的数据和世界知识与LLM语言技能相结合,生成的内容会更准确、更及时,并且更符合您的特定需求。RAG它的核心在于从用户自有知识源(如数据库、文档库等)中检索相关信息,并将这些信息用于辅助语言模型生成更准确、更有针对性的回答。例如,在一个问答系统中,当用户提出一个问题,RAG系统首先会在知识库中查找与该问题相关的内容,然后利用这些内容帮助语言模型生成回答。
一、检索增强生成如何工作?
RAG 通过几个主要步骤来增强生成式AI输出:
1.检索和预处理:RAG利用强大的搜索算法来查询外部数据,例如网页、知识库和数据库。检索后,相关信息将经过预处理,包括标记化、词干提取和删除停用词。
2.内容生成:经过预处理的检索信息随后无缝集成到预训练的LLM中。这种集成增强了LLM的背景,使其对主题有了更全面的理解。这种增强的背景使LLM能够生成更精确、更有信息量且更有吸引力的响应。
RAG 首先使用LLM生成的查询从数据库中检索相关信息。然后将检索到的信息集成到LLM的查询输入中,使其能够生成更准确、上下文相关的文本。检索通常由语义搜索引擎处理,该引擎使用存储在矢量数据库中的嵌入以及复杂的排名和查询重写功能,确保结果与查询相关并能回答用户的问题。
二、为什么使用 RAG?
RAG 具有多项优势,可增强传统的文本生成方法,尤其是在处理事实信息或数据驱动的响应时。
1.获取最新信息
LLM 受限于其预先训练的数据。这会导致响应过时且可能不准确。RAG 通过向LLM提供最新信息来克服这一问题。
2.事实依据
LLM 是生成富有创意且引人入胜的文本的强大工具,但有时在事实准确性方面存在问题。这是因为LLM是在大量文本数据上进行训练的,而这些数据可能包含不准确或偏见。
将“事实”作为输入提示的一部分提供给LLM可以减轻“人工智能幻觉”。这种方法的关键是确保向LLM提供最相关的事实,并且LLM输出完全基于这些事实,同时回答用户的问题并遵守系统指令和安全约束。
使用大模型的长上下文窗口 (LCW) 是向LLM提供源材料的绝佳方式。如果您需要提供超出 LCW 容量的信息,或者需要提高性能,则可以使用RAG方法减少标记数量,从而节省时间和成本。
三、开发阶段
1. 数据准备阶段
收集和整理知识源:
确定知识源的类型,如文本文件、网页、数据库记录等。例如,如果你正在开发一个医疗咨询系统,知识源可能包括医学文献、药品说明书、临床指南等。
对知识源进行清理和预处理。这可能涉及文本格式转换、去除噪声(如HTML标签、特殊符号等)、数据标准化(如统一日期格式、单位换算等)。
构建索引:
选择合适的索引工具和技术。常用的有向量数据库(如Milvus、Pinecone等)或传统的倒排索引。以向量数据库为例,需要将知识源中的文本转换为向量表示。
确定索引的维度和相似性度量方法。例如,在使用向量数据库时,要选择合适的向量嵌入模型(如Sentence Transformers模型)来将文本转换为向量,并且确定像余弦相似度这样的相似性度量指标,用于后续的检索。
2. 模型选择与集成
语言生成模型:
可以选择现有的预训练语言模型,如GPT系列(如果有API访问权限)、BERT、T5等。这些模型已经在大规模文本上进行了训练,具有很强的语言生成能力。
根据应用场景对语言模型进行微调。例如,如果你开发的是一个法律文件生成系统,可能需要使用法律文本对语言模型进行微调,使它能够生成符合法律术语和格式的内容。
检索模型或模块:
对于简单的基于关键词的检索,可以使用传统的信息检索技术,如TF-IDF(词频 逆文档频率)。但对于语义检索,需要使用更复杂的模型,如DPR(Dense Passage Retrieval)。DPR可以将用户的问题和知识源中的文本转换为向量,通过计算向量相似度来检索最相关的文本段落。
将检索模型和语言生成模型进行集成。通常是先通过检索模型从知识源中获取相关信息,然后将这些信息作为额外的输入提供给语言生成模型。例如,可以将检索到的文本段落与用户的问题拼接在一起,作为语言生成模型的输入。
3. 系统设计与开发
交互设计:
设计用户交互,方便用户提问和接收回答。可以是命令行界面、Web界面或者移动应用界面。例如,在Web界面中,用户可以通过输入框输入问题,然后系统在页面上显示回答。
设计与其他系统的接口。如果RAG系统需要与其他软件系统(如内容管理系统、数据库管理系统等)集成,需要定义好数据交互的接口和协议。
系统架构搭建:
构建后端服务,用于处理用户请求、执行检索和生成回答。后端可以使用成熟编程语言如Python、Java、Go等来实现。
考虑系统的可扩展性和性能。例如,采用分布式架构来处理大量的用户请求,或者使用缓存技术来提高检索速度。
4. 测试与优化阶段
功能测试:
对系统进行黑盒测试,检查系统是否能够正确地理解用户问题、检索相关信息并生成合理的回答。例如,提出一系列预定义的问题,查看系统的回答是否准确。
进行白盒测试,检查系统的各个组件(如检索模块、语言生成模块等)是否正常工作。例如,检查检索模块是否能够准确地找到相关的知识源内容。
性能优化:
优化检索性能。这可能包括调整索引参数、优化向量嵌入模型的参数或者采用更高效的检索算法。
优化语言生成性能。可以通过调整语言模型的超参数、增加训练数据或者改进输入文本的预处理方式来提高生成回答的质量和速度。
用户反馈与持续改进:
收集用户反馈,了解用户对系统回答的满意度和改进建议。例如,通过用户调查或者在系统界面中设置反馈渠道。
根据用户反馈和系统性能监测结果,持续改进系统,包括更新知识源、调整模型参数、优化系统架构等。
四、检索质量评估
检索质量评估是一个人工和机器相结合的工作过程,具体的评估内容包括以下几点:
1.相关性评估
主题匹配:
检查检索到的信息是否与用户的问题主题相符。例如,若用户询问“糖尿病患者的饮食注意事项”,检索到的信息应该主要围绕糖尿病饮食,如低糖食物推荐、饮食时间安排等。可以通过人工检查或使用自动化主题分类工具来判断。
衡量语义相关性。这涉及到理解问题和检索信息的语义内容。例如,对于问题“如何预防心血管疾病”,包含“有氧运动对心血管健康的益处”的检索信息是语义相关的,因为它涉及到预防心血管疾病的一种方式。可以使用词向量模型(如Word2Vec、GloVe)或预训练的语义相似度模型(如Sentence Transformers)来量化语义相关性。
粒度匹配:
考虑信息的详细程度是否合适。如果用户问的是一个宽泛的问题,如“人工智能的应用领域”,检索到的信息应该是涵盖多个应用领域(如医疗、金融、交通等)的概述。而对于具体问题,如“人工智能在癌症诊断中的具体应用方法”,则需要更详细的、针对癌症诊断场景的信息,像某种人工智能算法在肿瘤影像识别中的应用步骤。
2.准确性评估
事实核查:
验证检索信息中的事实是否正确。对于一些有明确答案的问题,如“地球的公转周期是多少”,可以直接与权威来源(如科学文献、百科全书等)对比检索到的答案。对于复杂的、涉及多个观点的问题,如“不同经济学派对通货膨胀的主要观点”,需要检查信息是否准确地反映了各学派的观点,这可能需要参考经济学领域的经典著作和研究论文。
检查信息是否存在矛盾。例如,在检索关于某种药物疗效的信息时,不能出现一部分内容说该药物能有效治疗某种疾病,而另一部分内容却否定这一说法的情况。
数据来源可靠性:
评估信息来源的权威性。例如,来自知名学术期刊、政府机构、行业标准组织的信息通常比个人博客或未经审核的论坛帖子更可靠。可以通过检查信息源的域名、作者资质、发布机构信誉等来判断。
考虑信息更新频率。对于一些快速发展的领域,如技术领域(如人工智能、区块链等),较新的信息可能更准确。例如,关于最新的编程语言特性的检索信息,应该来自最近更新的技术文档或新闻网站。
3.完整性评估
信息覆盖范围:
确定检索到的信息是否涵盖了问题的各个方面。例如,对于问题“如何进行有效的项目管理”,完整的信息应该包括项目规划、资源分配、进度监控、风险管理等多个方面,而不是仅涉及其中一两个部分。可以通过与该领域的知识框架或标准教程进行对比来评估。
检查是否有遗漏重要细节。比如在检索“申请专利的流程”时,不能缺少关键步骤,如专利检索、申请书撰写规范、审查流程等重要环节的信息。
深度足够性:
对于需要深入分析的问题,评估检索信息是否提供了足够的深度。例如,对于“量子计算的原理”这个问题,仅仅提供概念性的解释是不够的,还需要包括量子比特、量子门操作、量子算法等更深入的内容,以满足用户可能的深入了解需求。
4.时效性评估
时间敏感性信息:
对于一些受时间影响很大的领域,如新闻、股市、体育赛事等,要确保检索到的信息是最新的。例如,在检索“某场体育比赛的比分”时,过时的比分信息是没有价值的。可以通过检查信息中的时间戳或与最新的新闻源进行对比来判断。
考虑信息的有效期。例如,对于财经信息,某些数据(如汇率、股票价格)的有效期可能很短,而行业分析报告的有效期可能相对较长。
领域动态性:
在快速发展的领域,如科技领域,评估检索信息是否跟上了领域的最新动态。例如,在人工智能领域,新的算法和模型不断涌现,检索关于人工智能最新技术的信息应该反映这些新进展。可以通过关注领域内的顶尖研究机构发布、行业会议动态等来判断检索信息的时效性。
五、利用用户反馈改进检索质量
1.收集用户反馈的方式
问卷调查:
设计结构化的问卷,涵盖用户对检索结果满意度、准确性、相关性等方面的评价。例如,询问用户“您对检索到的信息是否满意?”并提供“非常满意”“满意”“不满意”“非常不满意”等选项。同时,可以设置开放性问题,如“您认为检索结果在哪些方面可以改进?”以获取更详细的反馈。
定期向用户发送问卷,例如每月或每季度一次,以跟踪用户反馈的变化趋势。还可以在用户完成一定数量的查询后自动弹出问卷,提高反馈收集的效率。
用户评论和评分系统:
在系统界面中设置评论框和评分功能,让用户能够直接对每次检索结果进行评价。例如,用户可以给检索结果打分(1-5分),并在评论框中写下具体的意见,如“检索到的信息太笼统,没有我想要的细节”。
对用户的评论和评分进行实时监测,及时发现负面反馈较多的问题点,以便快速采取改进措施。
用户行为分析:
跟踪用户在看到检索结果后的行为,如用户是否进一步点击相关链接、在页面上停留的时间、是否重新发起查询等。例如,如果用户在看到检索结果后很快离开页面,可能表示检索结果没有满足他们的需求。
利用分析工具来收集和分析这些行为数据,从中挖掘用户对检索质量的潜在反馈。
2.分析用户反馈以确定问题点
分类反馈内容:
将用户反馈按照相关性、准确性、完整性、时效性等信息检索质量的关键维度进行分类。例如,将所有关于检索结果与问题不相关的反馈归为一类,将涉及信息错误的反馈归为另一类。
对于每个类别,统计反馈的数量和频率,确定主要的问题类型。例如,如果发现关于检索结果不完整的反馈占比较高,就需要重点关注信息的完整性改进。
挖掘具体问题细节:
在每个问题类别中,深入分析反馈内容,找出具体的问题细节。例如,在相关性问题类别中,分析用户提到的哪些主题或关键词没有被正确检索到;在准确性问题中,确定是哪些具体的事实或数据出现错误。
结合用户行为分析数据,进一步验证问题细节。例如,如果用户频繁重新查询某一特定主题,且在反馈中提到检索结果不准确,那么就需要对该主题相关的检索和信息提供进行重点改进。
3.根据反馈改进系统
优化检索算法和模型:
如果用户反馈显示检索结果相关性较低,考虑调整检索算法的参数。例如,在基于向量的检索中,优化向量嵌入模型的超参数,如调整词向量的维度或更新训练数据,以提高语义相似度计算的准确性。
对于准确性问题,更新信息索引。如果发现某些信息源经常提供错误信息,要么更新这些信息源,要么调整检索权重,减少从这些不可靠源获取信息的可能性。
更新知识源:
若用户反馈信息完整性不足,补充或更新知识源。例如,对于某个特定领域的问题(如新兴的技术领域),添加最新的研究报告、行业动态等知识内容。
定期审查和清理知识源,删除过时或错误的信息。根据用户反馈中关于时效性的问题,确定哪些知识内容需要更新,比如在金融领域,及时更新股票数据、财经政策等信息。
调整系统界面和提示信息:
如果用户对检索结果的理解存在困难,优化系统界面设计。例如,对检索到的信息进行更好的分类和展示,或者提供更清晰的摘要,帮助用户快速判断信息的相关性和价值。
根据用户反馈中常见的误解或问题,更新系统的提示信息。例如,如果用户经常误解某个查询功能,修改该功能的提示文字,使其更加准确和易懂。