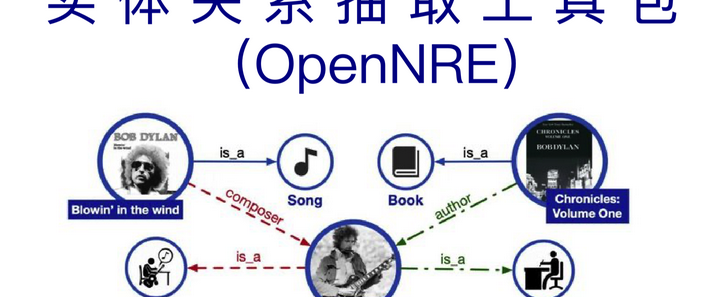
IKAnalyzer是一个开源的、基于 Java 语言开发的轻量级中文分词工具包。它采用了特有的“正向迭代最细粒度切分算法”,支持细粒度和智能分词两种切分模式,具有较高的分词速度和较小的内存占用,同时支持用户词典扩展定义。在 Maven 项目中添加相关依赖后,即可使用 IKAnalyzer 进行中文分词操作。作为一个基于 Java 语言开发的工具包,它可以很方便地集成到各种 Java 项目中,与其他的 Java 技术和框架进行配合使用。无论是在 Web 应用、桌面应用还是企业级应用中,都能够轻松地集成 IKAnalyzer 进行中文分词处理。