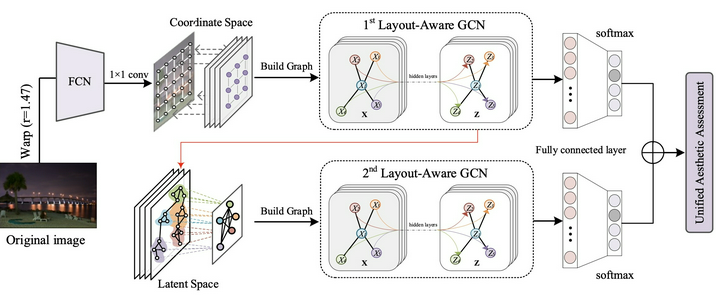
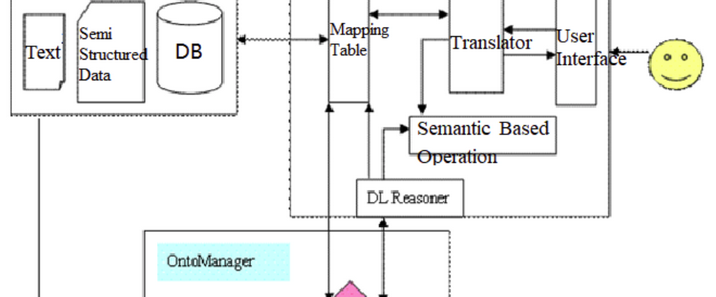
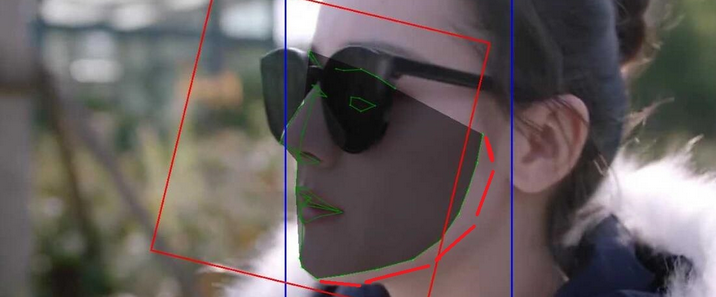
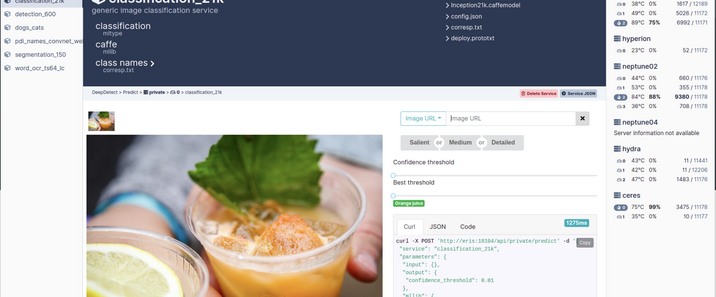
KMSphere是中国科学院计算技术研究所智能科学实验室研制的知识管理系统,包括OntoSphere、OntoManager和OntoService三个部分,分别用于半自动本体获取、可视化本体管理编辑和基于多主体系统的知识共享服务。知识发现是从数据中挖掘知识的过程。企业知识中台是一种基于人工智能技术形成的智能化知识解决方案,它具有全链路的知识管理能力,覆盖知识的高效生产、灵活组织和智能应用。知识中台能够自动化地从数据中提取知识,在业务场景中的人机互动里主动推荐知识,帮助业务人员高效、精准、智能地制定决策,提升企业的经营效率与业务创新能力。随着企业数字化进程的推进,IT系统数量逐步增加,数据通常分散在不同的系统中。知识中台汇聚全量数据,依靠智能技术从数据中自动挖掘各类型知识,服务前台业务系统。