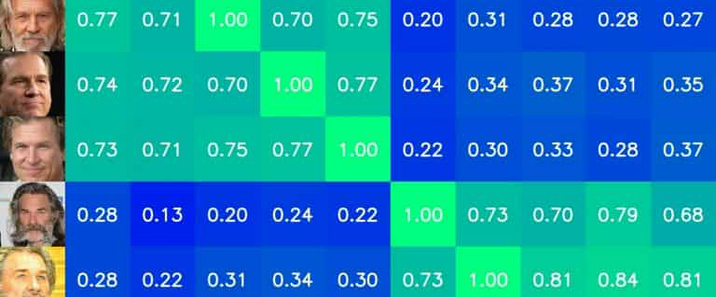
Multi Task Cascaded Convolutional Networks(MTCNN)是一种多任务的级联卷积神经网络,它同时处理人脸检测、面部关键点定位和人脸姿态估计三个任务。由于MTCNN在人脸检测和面部关键点定位方面的高精度和较好的性能,它被广泛应用于各种需要人脸处理的应用中,如人脸识别门禁系统、社交平台的人脸特效(如添加滤镜、美颜等)、视频会议软件中的人脸跟踪等。在直播软件中,MTCNN可以实时检测主播的人脸,为后续的美颜、特效添加等操作提供基础。
PostBooks建立在 xTuple ERP 的基础上,涵盖财务、销售、采购、库存、制造、项目管理等多个业务领域,为中小型企业提供全面的业务管理解决方案。PostBooks是一个开源项目,采用 xTuple Public License 许可证,用户可以自由使用、修改和分发软件。用户界面设计直观且易于使用,无论是通过图形界面还是 Web 界面,用户都可以方便地进行交互和操作,执行各种业务任务。
DALLE:由OpenAI开发的DALLE是一个能够根据自然语言描述创建逼真图像和艺术的AI系统。 尽管DALLE生成的图像在保真度上可能不如Stable Diffusion或Midjourney,但其优势在于简单性,并且编辑生成的图像比“重绘”图像更为简单。DALLE 不是开源的,OpenAI 提供了部分功能的 API 供开发者使用。这意味着开发者可以通过 API 来访问 DALLE 的图像生成能力,以创建自己的应用程序。
dlib是一个包含多种机器学习算法的库,其中的人脸检测部分基于HOG(Histogram of Oriented Gradients)特征和线性分类器。HOG特征是一种用于描述图像局部梯度方向分布的特征,它通过计算图像局部区域内像素梯度的方向直方图来表示图像特征。对于人脸检测,dlib首先提取图像中的HOG特征,然后将这些特征输入到一个训练好的线性分类器中进行判断。同时,dlib还支持基于深度学习的人脸检测方法,如使用预训练的深度神经网络模型进行人脸检测。
Haar Cascades是一种基于机器学习的目标检测算法,它使用了Haar特征。Haar特征是一种简单的矩形特征,通过计算图像中相邻矩形区域的像素灰度差值来表示图像的局部特征。例如,对于人脸检测,眼睛区域通常比脸颊区域暗,这种灰度差异可以通过Haar特征来捕捉。 它利用了积分图像(Integral Image)的概念,这使得Haar特征能够快速计算。积分图像可以在常数时间内计算出任何矩形区域的像素和,大大提高了特征计算的效率。