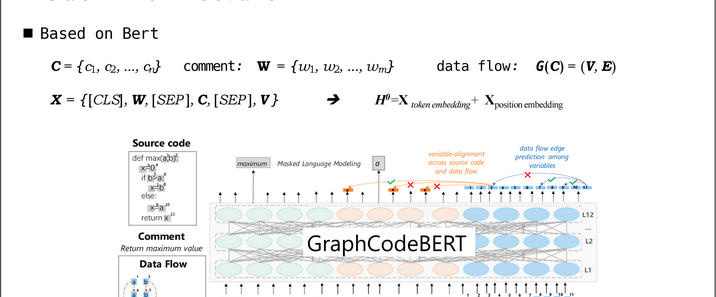
CodeT5是由Salesforce研究团队开发的一种开源的预训练代码生成模型,它基于T5架构,并在大规模的代码数据集上进行了预训练。CodeT5能够将代码的输入转换为相应的输出,例如根据函数的签名生成函数体、根据代码片段生成完整的代码等。它在代码生成任务中表现出色,能够生成高质量、符合语法和逻辑的代码。CodeT5在多种代码相关任务上取得了先进的性能表现,如代码生成、代码补全、文本到代码检索等任务。经过指令调整的CodeT5+ 16b在HumanEval代码生成任务中取得了35.0%的一次通过率和54.5%的十次通过率,超过了许多其他开放代码语言模型以及闭源的OpenAI codecushman001模型。