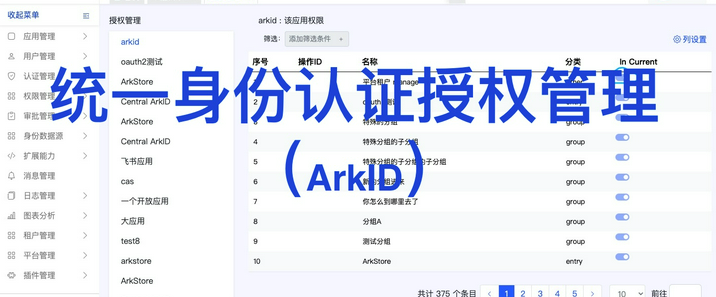
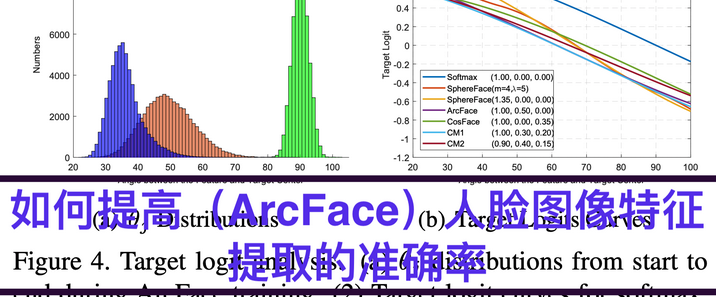
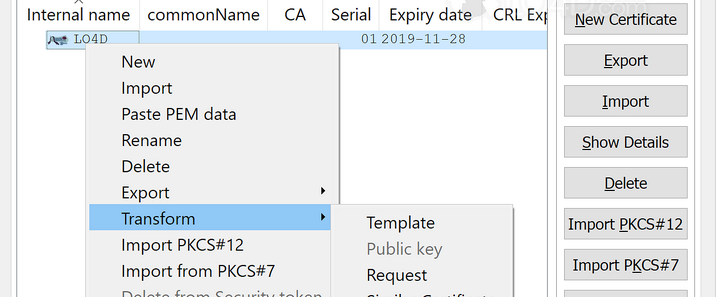
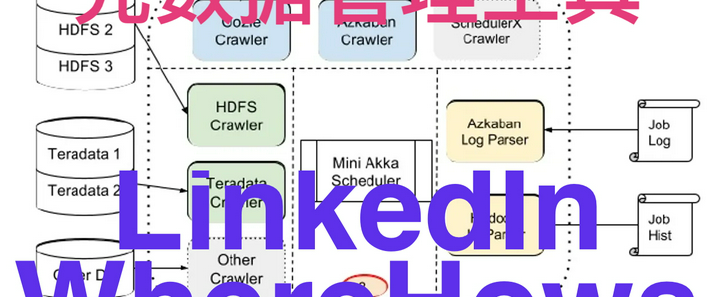
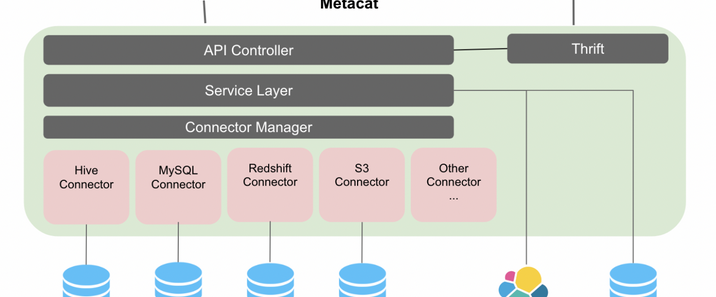
ArkID是一个用于统一身份认证和授权管理的系统。它的主要目的是在复杂的企业级或多系统应用环境中,对用户的身份进行集中验证,并对用户访问各种资源的权限进行精细的管理。例如,在一个大型企业中有多个不同的业务系统,如人力资源管理系统、财务管理系统、客户关系管理系统等。员工需要使用不同的账号和密码来访问这些系统,这不仅麻烦,而且存在安全隐患。ArkID可以将这些分散的身份认证整合起来,员工只需要使用一组账号和密码(单点登录)就可以访问所有授权的系统。支持LDAP、OAuth2、SAML、OpenID等多种标准协议,具有细粒度权限控制和完整的WEB管理功能。