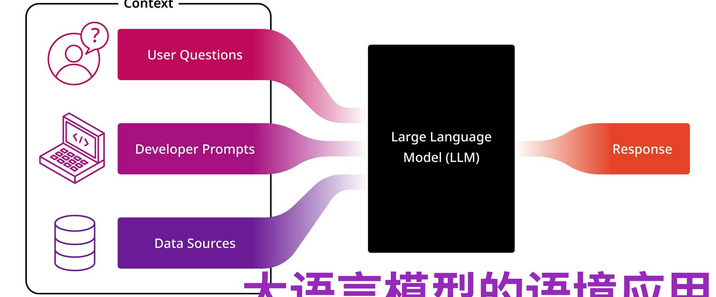
随着人工智能技术的飞速发展,特别是自然语言处理(NLP)领域的突破,大型语言模型(Large Language Models, LLMs)已经成为科技界炙手可热的话题之一。这些模型能够执行广泛的任务,从文本生成到对话理解等,为众多行业提供了前所未有的机会。然而,开发和维护这样复杂的系统需要巨大的投入,因此探索有效的商业模式对于确保其可持续发展至关重要。
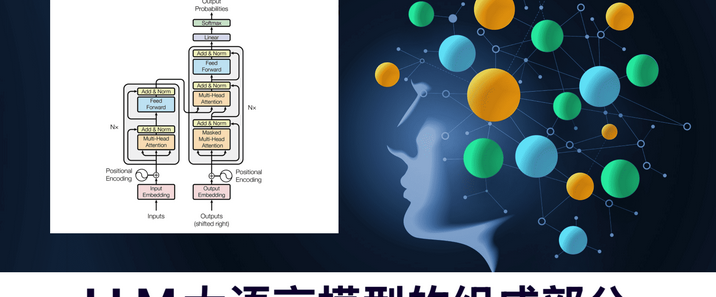
LLM(Large Language Model)大语言模型由输入层将文本转为向量,基于Transformer架构的编码器提取语义与上下文信息,解码器据此生成输出,输出层经Softmax和搜索策略将向量转为最终文本;通过在大规模无监督语料上预训练学习通用知识,再针对具体任务用有标注数据微调;记忆与缓存机制处理长序列并提高效率,评估模块用困惑度等指标衡量性能,优化模块据此调整超参数、改进结构 。