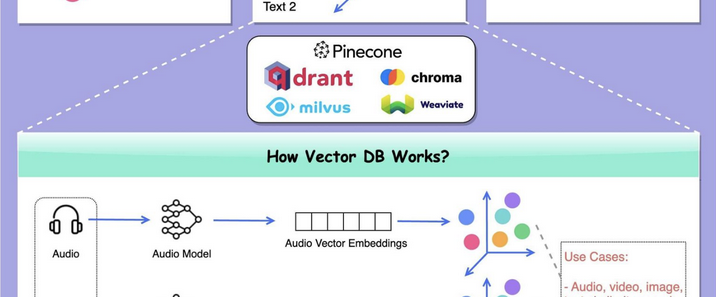
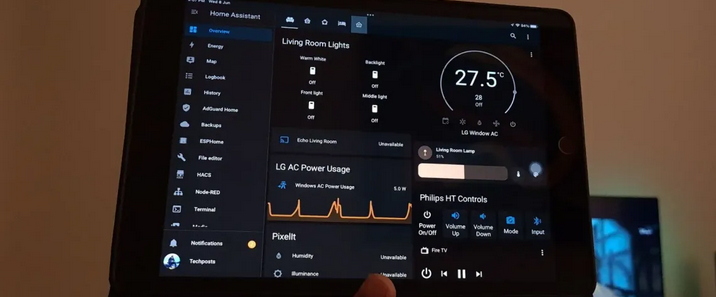
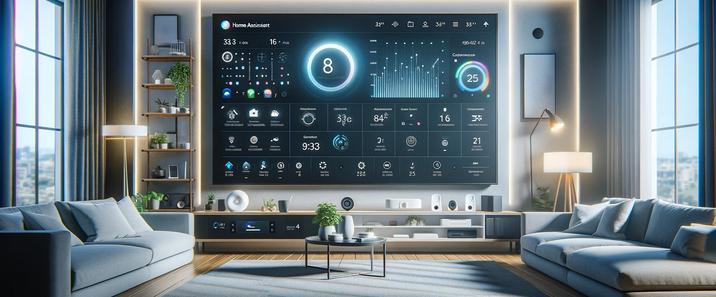
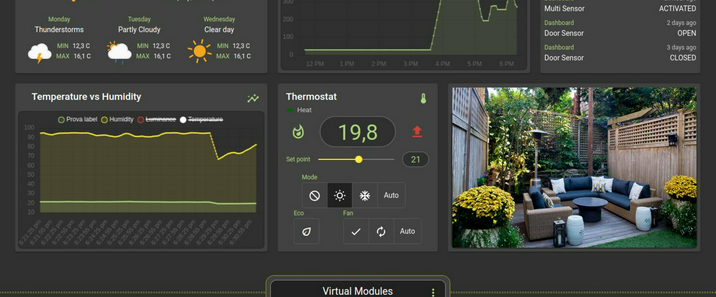
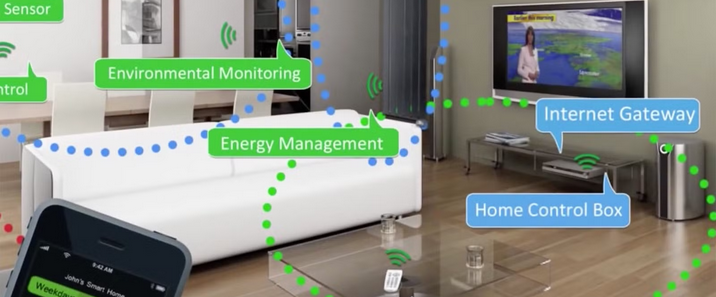
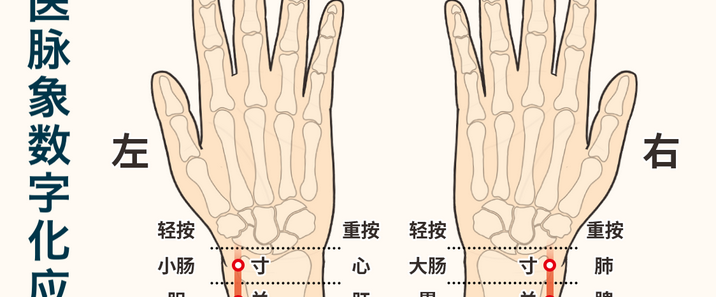
在当下,健康愈发成为人们生活的核心关注点,而智能床垫作为健康产业中极具创新性与变革性的产品。它不再仅仅是一张普通的床垫,而是融合了先进的传感器技术、智能算法以及人性化设计的高科技结晶。通过内置的各类精密传感器,智能床垫能够精准地监测睡眠者的心率、呼吸、体动等关键生理数据,就像一位贴身的健康管家,实时守护着睡眠者的健康状况。同时,基于这些数据,智能床垫运用智能算法,对睡眠质量进行深度分析,并依据个人的睡眠习惯和身体状况,自动调节床垫的软硬度、温度等参数,为用户打造真正个性化的舒适睡眠体验。在快节奏的现代生活中,人们饱受睡眠问题的困扰,智能床垫的出现,彻底改变了传统床垫的单一功能模式,为人们带来了前所未有的睡眠革新,开启了健康睡眠的全新篇章,在健康产业的发展历程中,留下了浓墨重彩的一笔。