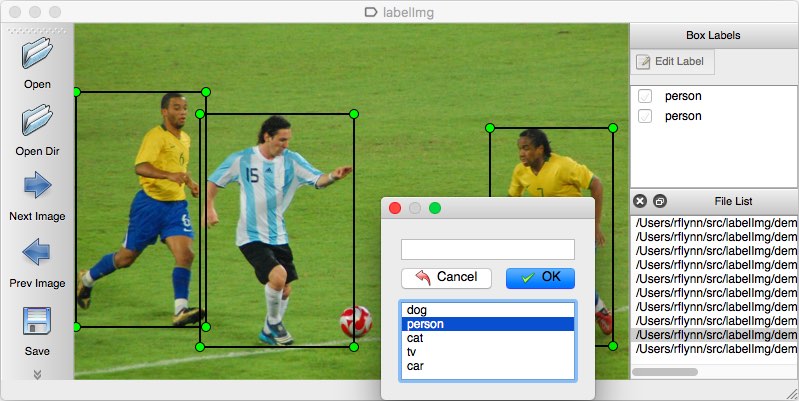
文本标注是自然语言处理领域中的一项基础且关键的任务,它主要是指专业的标注人员或借助特定的标注工具,按照一定的规则和标准,对文本内容进行标记和注释,从而赋予文本特定的语义信息和结构信息。具体来说,标注人员会根据任务需求,在文本中识别并标记出各种元素,比如将文本中的人名、地名、组织机构名等标注为不同的实体类型,确定文本中不同实体之间存在的关系,像因果关系、所属关系等,还会对文本中的特定事件进行标注,记录事件的类型、发生时间、参与主体等信息,同时可能会标注出文本的情感倾向,如积极、消极或中性等。通过文本标注,可以将非结构化的文本数据转化为结构化的数据,为自然语言处理中的命名实体识别、关系抽取、情感分析、信息检索、机器翻译等各种任务提供基础数据支持,帮助计算机更好地理解和处理文本信息,进而推动自然语言处理技术的发展和应用。