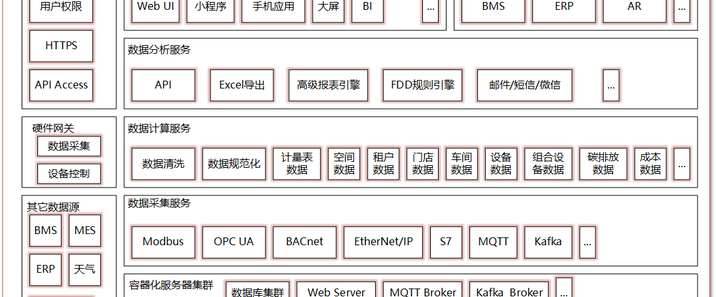
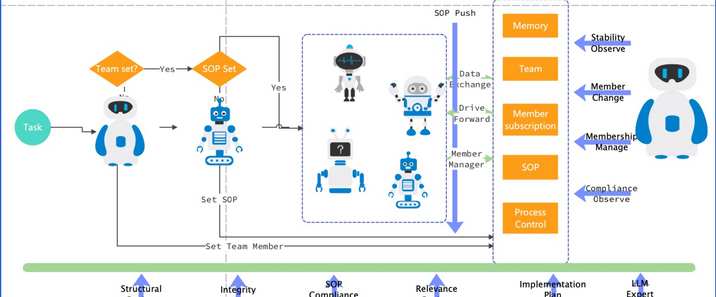
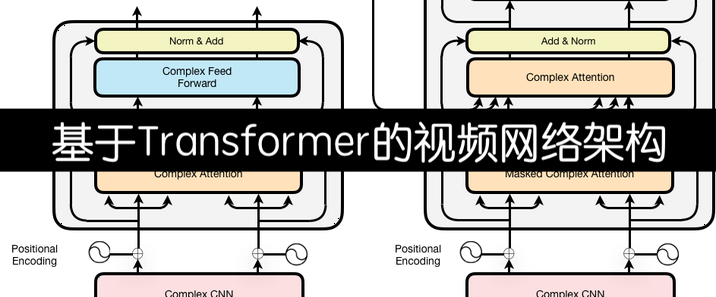
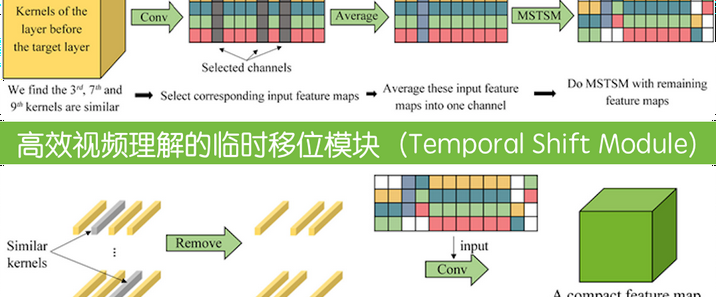
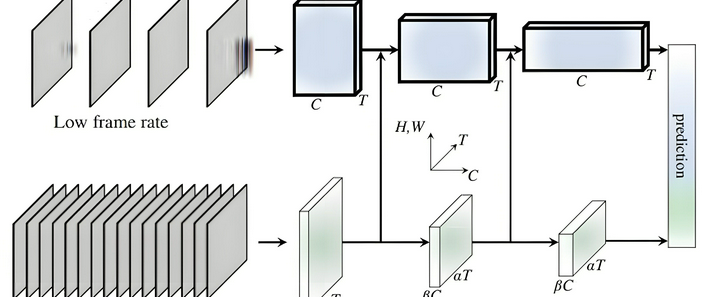
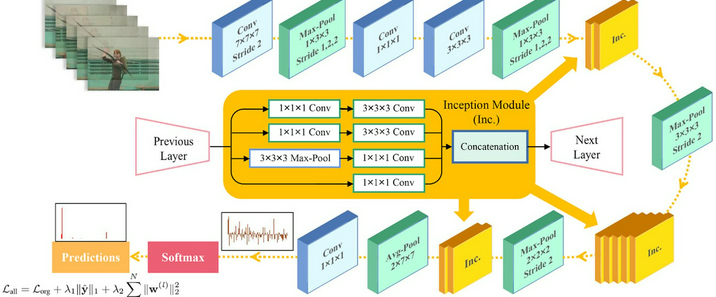
智能问答机器人已成为提升用户体验、提高工作效率的重要工具。基于向量数据库的智能问答机器人能够快速、准确地回答用户问题,为用户提供高效的服务。一、向量数据库基础1.向量表示与语义理解向量数据库的核心在于将各种信息,如文本、图像、音频等,转化为向量形式进行存储和处理。以文本为例,通过自然语言处理(NLP)技术中的词嵌入(Word Embedding)、句嵌入(Sentence Embedding)等方法,将单词、句子甚至整个文档转换为多维空间中的向量。这些向量不仅包含了文本的语义信息,还能通过向量之间的距离(如余弦相似度、欧氏距离等)来衡量文本之间的语义相似度。例如,使用 BERT、GPT 等预训练模型对文本进行编码,得到的向量能够准确反映文本的语义特征,使得语义相近的文本在向量空间中距离较近。