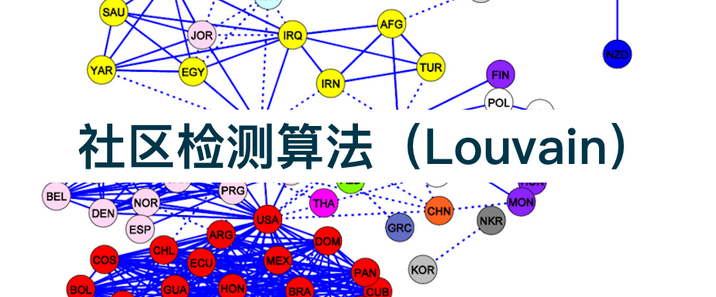
GraphRAG(Graph-based Retrieval-Augmented Generation,基于图的检索增强生成)是知识图谱(Knowledge Graph, KAG)领域的重要分支,通过将知识图谱的结构化关系与大语言模型(LLM)结合,显著提升复杂场景下的生成准确性和可解释性。GraphRAG通过知识图谱的结构化优势与大语言模型的生成能力互补,在复杂推理、多模态检索、可解释性等方面树立了新标杆。其核心价值不仅在于技术性能的提升,更在于为医疗、金融、科研等领域提供了可落地的“认知智能”解决方案。随着动态图处理、多模态融合等技术的进一步突破,GraphRAG有望推动生成式AI从“感知智能”向“决策智能”跨越,重塑人机协作的新范式。