一、模型核心定义与理论基础1.核心定义运动训练负荷积分模型(Sports Training Load Scoring Model)是基于“刺激-适应-恢复”动态平衡理论,通过积分运算量化运动员在特定周期内承受的生理、心理、生物力学负荷总和的系统化工具。其核心价值在于突破传统经验式负荷调控的局限,将多维度负荷数据转化为可量化、可追踪的积分指标,实现从“经验驱动”到“数据驱动”的训练管理升级。
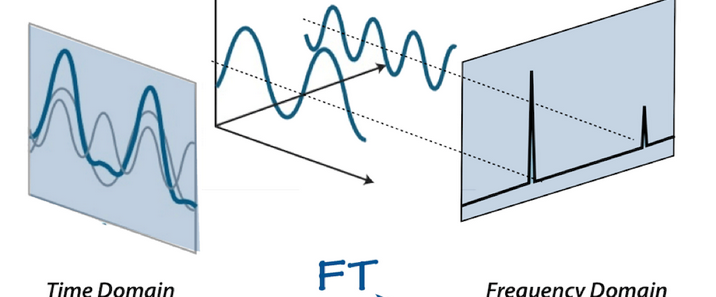
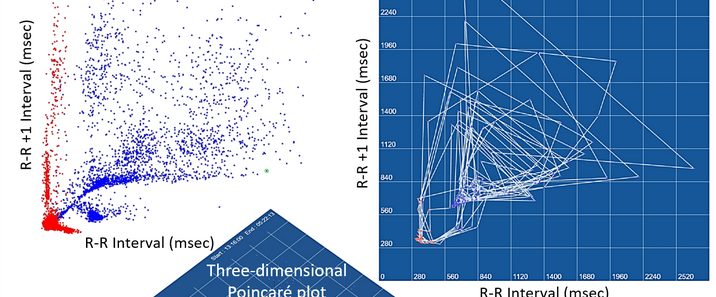
Pan-Tompkins算法是由Pan和Tompkins于1985年提出的一种经典实时QRS波检测算法,发表于《IEEE Transactions on Biomedical Engineering》期刊,核心用于心电图(ECG)信号中R波的精准定位,为心率计算、心律失常检测等临床分析提供关键支撑。其设计理念基于QRS波群的时域特征(幅值、斜率、时间间隔),通过滤波增强特征、动态阈值自适应识别,兼顾检测精度与实时性,广泛应用于医疗监护设备、心电信号分析系统中。