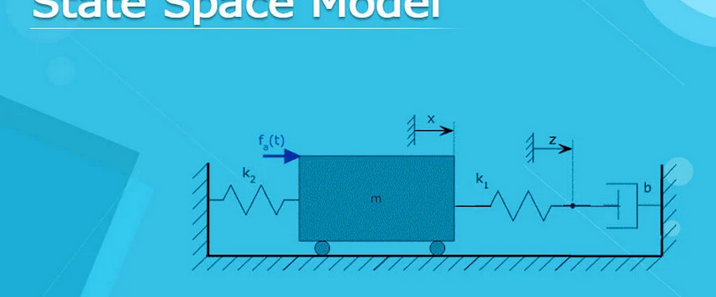
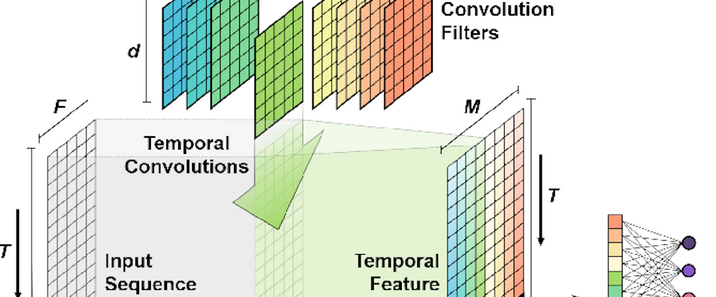
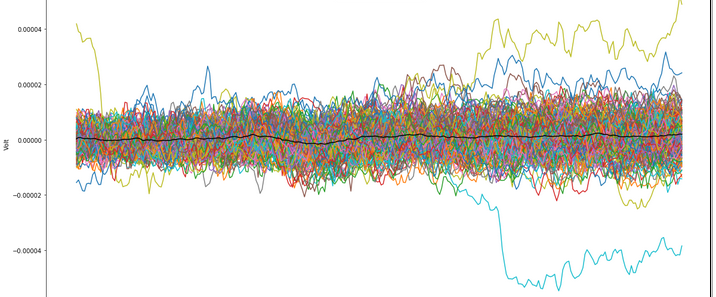
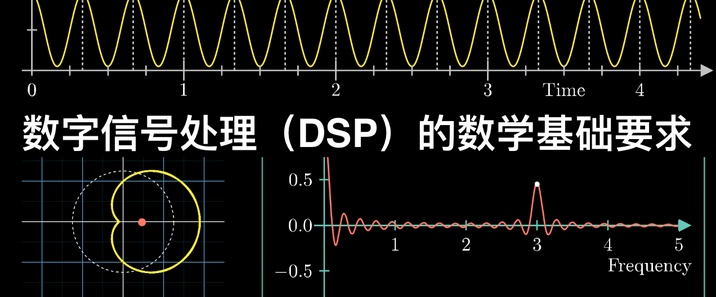
一、TCN的定义与核心定位时序卷积网络(Temporal Convolutional Network,简称TCN)是一种专门用于处理**时序数据**的卷积神经网络(CNN)变体,由Bai等人于2018年在论文《An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling》中正式提出。其核心设计目标是通过卷积操作捕捉时序数据中的长期依赖关系,同时保留CNN固有的并行计算优势,弥补循环神经网络(RNN、LSTM、GRU等)在长序列处理中存在的梯度消失/爆炸、并行性差等问题。