自注意力机制(Self-Attention Mechanism)是深度学习中用于捕捉序列数据内部依赖关系的核心技术。
一、发展历程
自注意力机制的发展并非一蹴而就,而是在解决序列建模痛点的过程中逐步迭代完善,大致可分为三个核心阶段,从早期探索到技术爆发,再到全面泛化,逐步成为深度学习序列建模的核心技术。
1.早期探索阶段(2017年之前):注意力机制铺垫与痛点凸显 自注意力的思想源于注意力机制的早期研究,这一阶段尚未形成完整的自注意力框架,但为后续发展奠定了重要基础。在此之前,序列数据建模主要依赖RNN及其变体(LSTM、GRU)和CNN,其中RNN类模型存在顺序计算导致的训练效率低、长距离依赖捕捉困难等瓶颈,CNN则受限于感受野,需多层堆叠才能捕捉长距离关联,计算开销较大。为解决这些问题,研究人员引入注意力机制,用于增强编码器-解码器框架的性能,但此时的注意力机制多为外部注意力,依赖外部信息源,无法直接捕捉输入序列内部的关联,自注意力的核心思想仍处于萌芽状态,尚未形成标准化的计算范式。
2.技术爆发阶段(2017年):标准自注意力机制正式诞生 2017年,谷歌研究团队的八位研究员发表论文《Attention Is All You Need》,首次正式提出自注意力机制,并将其作为Transformer架构的核心组件,彻底摒弃了RNN和CNN的主导地位,标志着自注意力机制进入成熟阶段。该论文提出的标准自注意力机制,通过Q、K、V向量的设计和缩放点积运算,实现了序列中任意两个位置的直接关联建模,支持并行计算,既解决了RNN的效率瓶颈,又突破了CNN长距离依赖捕捉的局限,同时引入多头注意力、位置编码等优化技术,进一步提升了模型性能。这一突破不仅在机器翻译任务上刷新了当时的性能记录,更奠定了后续大型预训练模型的技术基础,引发了深度学习领域的范式转变。
3.泛化与优化阶段(2017年至今):变体迭代与多领域渗透 自Transformer架构和自注意力机制提出后,研究人员围绕性能优化、场景适配等方向,推动自注意力机制不断迭代,衍生出多种变体。一方面,针对标准自注意力计算复杂度高(O(n²d))的问题,稀疏自注意力、线性注意力等轻量化变体相继出现,大幅提升了长序列处理效率;另一方面,结合不同任务需求,因果注意力、交叉注意力等变体逐步发展,适配自回归生成、图文融合等各类场景。同时,自注意力机制的应用场景从自然语言处理(NLP)逐步拓展到计算机视觉(CV)、语音处理、推荐系统等多个领域,如Vision Transformer(ViT)将图像转化为序列,通过自注意力实现高精度图像识别,成为多领域序列建模的核心技术,推动了生成式AI等领域的飞速发展。
二、基础定义
自注意力机制的定义:针对序列数据(如文本、语音、时序信号等),让序列中的每个位置(token)作为“查询者”,通过计算与序列中所有位置(包括自身)的关联程度(注意力权重),将所有位置的信息加权融合,得到该位置的上下文表征,从而捕捉序列内部的长距离依赖、局部关联等潜在关系。
核心目标:解决传统RNN、CNN在处理长序列时“长距离依赖捕捉能力弱”“计算效率低”的问题,实现序列中任意两个位置的直接关联建模,且建模过程不依赖序列顺序(可并行计算),提升模型对复杂序列的理解能力。
三、核心组件
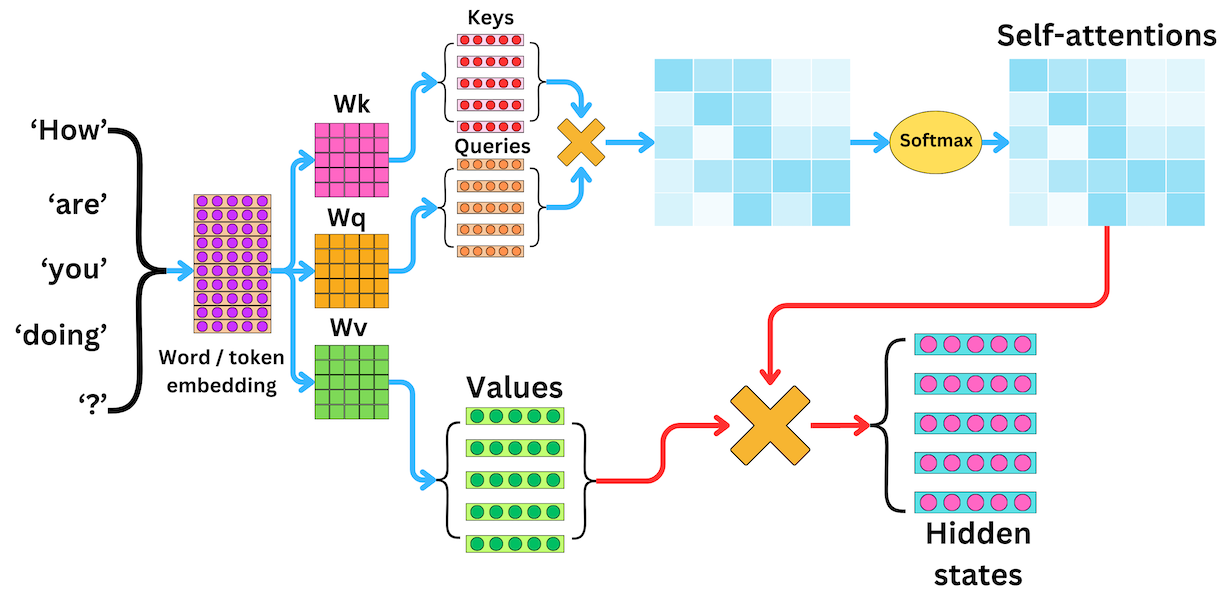
自注意力机制的核心运算依赖3个关键向量(由输入序列通过线性变换生成),以及注意力权重的计算与归一化组件,具体如下:
1.查询向量(Query, Q):对应“查询者”,每个序列位置的输入经过线性变换后得到Q,用于主动查询序列中其他位置的信息,本质是该位置的特征表征。
2.键向量(Key, K):对应“被查询者”,每个序列位置的输入经过另一组线性变换得到K,用于与Q进行匹配,计算二者的相似度(关联程度),作为注意力权重的基础。
3.值向量(Value, V):对应“被查询者的具体信息”,每个序列位置的输入经过第三组线性变换得到V,当注意力权重确定后,V将通过权重加权融合,生成最终的上下文表征。
4.注意力权重计算与归一化组件:核心是通过Q与K的相似度计算得到初始权重,再通过Softmax函数归一化,确保权重之和为1,使得每个位置的上下文表征能合理融合序列中各位置的信息。
四、核心计算流程(标准自注意力)
标准自注意力的计算过程可分为5个步骤,流程清晰且可并行执行,具体如下:
1.输入编码:假设输入序列为X = [x₁, x₂, ..., xₙ](n为序列长度,每个xᵢ为该位置的特征向量),通过3个独立的线性变换矩阵W_q、W_k、W_v,分别生成Q、K、V三个矩阵,即Q = X·W_q,K = X·W_k,V = X·V_v(维度均为n×d,d为向量维度)。
2.相似度计算(注意力得分):将Q与K的转置矩阵进行点积运算,得到注意力得分矩阵S(维度n×n),S[i][j]表示第i个位置的Q与第j个位置的K的相似度,即S = Q·Kᵀ。
3.缩放(Scaling):为避免Q与K点积后数值过大,导致Softmax函数饱和(梯度消失),将得分矩阵S除以√d(d为Q/K的维度),得到缩放后的得分矩阵S' = S / √d。
4.权重归一化:对缩放后的得分矩阵S'的每一行(每个查询位置)应用Softmax函数,得到注意力权重矩阵A(维度n×n),A[i][j]表示第i个位置对第j个位置的关注程度,且每行权重之和为1,即A = Softmax(S')。
5.上下文表征生成:将注意力权重矩阵A与值向量矩阵V进行点积运算,得到最终的上下文表征矩阵Z(维度n×d),Z的每一行对应原序列中该位置的最终特征,即Z = A·V。
五、关键优化技术
标准自注意力虽能有效捕捉依赖,但存在计算复杂度高(O(n²d),n为序列长度)、易过拟合等问题,因此体系中包含多个关键优化技术,核心如下:
1.多头注意力(Multi-Head Attention):将Q、K、V通过多组独立的线性变换,生成多组Q、K、V,分别计算自注意力并得到多组上下文表征,最后将多组表征拼接,通过线性变换融合,提升模型对不同类型依赖的捕捉能力(如局部依赖、长距离依赖),同时降低单一注意力头的偏差。
2.位置编码(Positional Encoding):自注意力本身不具备时序感知能力(对序列顺序不敏感),因此需在输入中加入位置编码,将序列位置信息嵌入到输入特征中,确保模型能捕捉序列的时序关系,常用正弦/余弦位置编码、可学习位置编码两种方式。
3.注意力掩码(Attention Mask):用于过滤无效信息,避免模型关注不需要的位置,主要分为两种:① 填充掩码(Padding Mask):过滤序列中的填充token(如文本中的[PAD]),避免其影响注意力计算;② 因果掩码(Causal Mask):即之前提到的因果注意力,用于自回归任务,限制模型仅关注当前及之前的位置,避免访问未来信息。
4.优化计算复杂度:针对长序列场景,提出稀疏自注意力(如Local Attention、Strided Attention)、线性注意力(如Linear Attention)等变体,将计算复杂度从O(n²d)降至O(nd)或O(n log n d),提升长序列处理效率。
六、主要变体延伸
自注意力机制在不同任务场景中衍生出多种变体,核心变体围绕“适配不同任务需求、优化性能”展开,常见的有:
1.因果注意力(Causal Attention):又称遮蔽自注意力,通过因果掩码限制信息流向,仅允许当前位置关注自身及历史位置,是GPT等自回归语言模型的核心组件,适用于文本生成、语音合成等时序生成任务。
2.交叉注意力(Cross-Attention):区别于自注意力(仅关注同一序列内部),交叉注意力关注两个不同序列的关联(如文本序列与图像序列、 encoder输出与decoder输入),是Transformer编码器-解码器结构的核心,适用于机器翻译、图文生成等任务。
3.自注意力的轻量化变体:如Depthwise Separable Attention、Squeeze-and-Excitation Attention等,通过简化注意力计算、减少参数数量,适配移动端、边缘设备等资源受限场景。
4.融合因果推断的变体:如因果注意力机制(前文所述),在注意力权重计算中融入因果约束,提升模型的解释性和预测可靠性,适用于时序预测、决策建模等场景。
七、应用场景
自注意力机制的体系价值最终体现在各类实际任务中,其应用已覆盖多个领域,核心场景包括:
1.自然语言处理(NLP):是Transformer模型的核心组件,支撑机器翻译、文本分类、情感分析、文本生成(GPT系列)、对话系统、命名实体识别等几乎所有NLP任务,彻底改变了传统NLP的技术路线。
2.计算机视觉(CV):用于图像分类、目标检测、语义分割、视频分析等任务,如Vision Transformer(ViT)将图像分割为patch序列,通过自注意力捕捉patch间的关联,实现高精度图像识别;在视频任务中,捕捉帧间时序依赖。
3.语音与时序信号处理:用于语音识别、语音合成、时序预测(如股价预测、气象预测)、强化学习中的序列决策等,捕捉语音序列、时序信号的长距离依赖和动态变化规律。
4.其他领域:如推荐系统(捕捉用户行为序列与物品的关联)、医学影像分析(捕捉影像序列中的病变关联)等,凡需处理序列数据、捕捉内部依赖的场景,均能用到自注意力机制。
总结
自注意力机制,以“QKV向量”和“注意力权重计算”为核心,以“多头注意力、位置编码、掩码”为优化手段,以“各类变体”为场景适配延伸,结合其从探索到爆发、再到泛化的发展历程,最终通过标准化的计算流程,支撑多领域序列任务的高效建模,是当代深度学习中序列建模的核心技术框架。