层级/分层注意力(Hierarchical Attention,简称HA)是注意力机制的重要扩展形式,核心思想是模拟人类“从整体到局部”的注意力分配逻辑,在数据的不同层级上分别应用注意力机制,通过分层处理捕捉数据的多层次结构信息,实现对局部细节与全局上下文的双重关注,尤其适用于本身具有明确层级结构的数据处理场景。
与传统单一尺度的注意力机制(如自注意力)不同,层级注意力不将所有输入信息视为同一维度的序列,而是根据数据的天然层级(如文本的“单词→句子→文档”、视频的“像素→帧→片段→视频”、图像的“像素块→局部区域→全局图像”),分阶段分配注意力权重,优先聚焦关键层级、关键信息,过滤冗余内容,同时保留数据的层级关联特性。
一、原理
层级注意力的核心是“分层建模、逐级聚焦”,整体流程可分为三个关键步骤,核心逻辑围绕“层级划分→逐层注意力计算→特征聚合”展开:
1.层级划分:根据输入数据的天然结构,将其划分为多个嵌套的层级,不同层级对应不同粒度的信息。例如文本数据可划分为“词级→句级→文档级”,图像数据可划分为“像素块级→局部区域级→全局图像级”,视频数据可划分为“帧级→片段级→视频级”,确保每个层级的信息具有相对独立的语义或特征价值。
2.逐层注意力计算:从最细粒度的底层开始,对每个层级单独计算注意力权重,筛选该层级的关键信息。底层注意力的输出结果将作为上一层级的输入,上层注意力会在底层关键信息的基础上,进一步筛选更具全局价值的内容,形成“底层聚焦细节、上层聚焦全局”的递进式注意力分配模式。
3.特征聚合:将各层级经过注意力筛选后的特征进行融合,形成最终的全局特征表示。这种聚合不是简单的拼接,而是结合各层级的注意力权重,突出关键层级和关键信息的贡献,既保留底层的细粒度细节,又兼顾上层的全局上下文,避免单一尺度注意力导致的信息丢失或冗余问题。
其本质是通过分层处理,将复杂的长序列或高维度数据拆解为可管理的子模块,降低注意力计算的复杂度,同时通过逐级聚焦,提升模型对关键信息的捕捉能力,增强特征表示的有效性和可解释性。
二、典型架构:层次注意力网络(HAN)
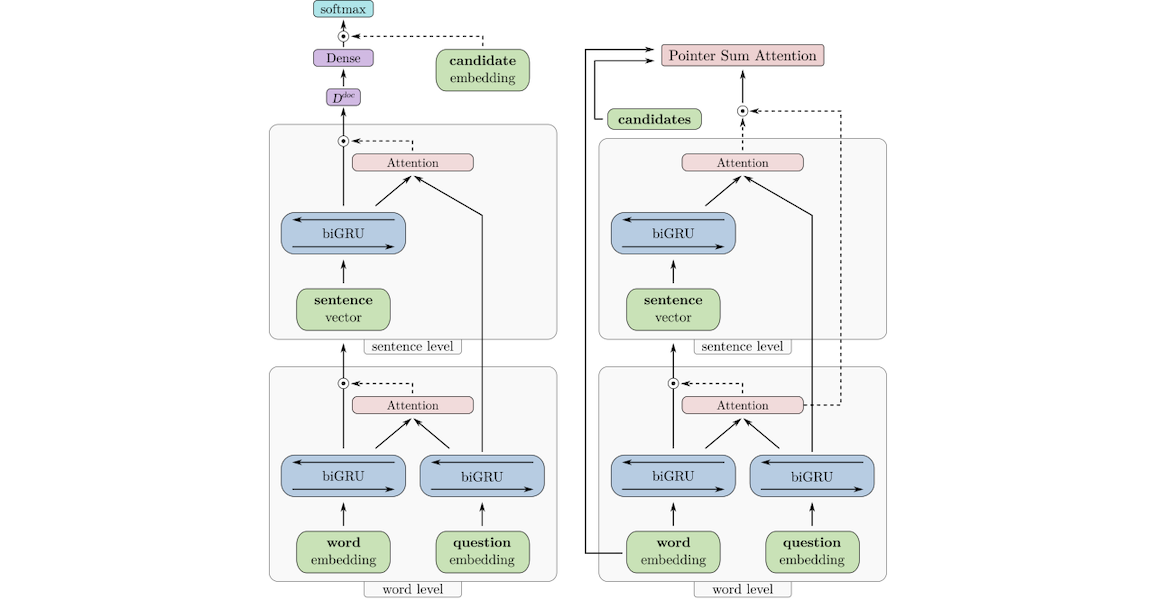
层次注意力网络(Hierarchical Attention Network,HAN)是层级注意力的经典实现,主要用于文本分类任务,完美契合文本的“词→句→文档”层级结构,其架构可分为四个核心模块,具体如下:
1.词编码器(Word Encoder):将句子中的每个单词通过嵌入矩阵转换为词向量,再通过双向GRU(循环神经网络变种)编码,融合单词的前后文信息,生成每个单词的上下文注释向量,捕捉单词层面的局部语义。
2.词级注意力层(Word-level Attention):并非所有单词对句子语义的贡献均等,该层通过单层MLP(多层感知机)计算每个单词注释向量的隐藏表示,再通过与词级上下文向量的相似度计算,得到每个单词的注意力权重,通过Softmax归一化后,对单词注释向量进行加权求和,生成句子向量,突出句子中的关键单词。
3.句编码器(Sentence Encoder):采用与词编码器类似的双向GRU结构,对生成的句子向量进行编码,融合句子的前后文信息,生成每个句子的上下文注释向量,捕捉句子层面的语义关联。
4.句级注意力层(Sentence-level Attention):与词级注意力逻辑一致,通过计算句子注释向量与句级上下文向量的相似度,得到每个句子的注意力权重,加权求和后生成文档向量,突出文档中的关键句子,最终用于文本分类任务。
HAN的核心优势是,通过词级和句级的双重注意力,不仅能提升分类性能,还能通过注意力权重可视化,明确识别出影响最终决策的关键单词和句子,大幅增强模型的可解释性。
三、关键特性
1.多尺度特征捕捉:通过分层设计,同时关注微观细粒度特征(如文本中的单词、图像中的像素块)和宏观全局特征(如文本中的文档主题、图像中的整体场景),实现对数据多维度信息的全面捕捉,避免单一尺度注意力的局限性。
2.可解释性强:各层级的注意力权重可通过可视化手段呈现,能够清晰展示模型在每个层级关注的关键信息,例如文本任务中模型关注的关键单词和句子、图像任务中关注的关键区域,解决了传统注意力机制“黑箱”问题。
3.复杂度可控:虽然需要在多个层级重复计算注意力,理论复杂度高于普通注意力,但通过合理的层级划分、参数共享或下采样操作,可有效降低总体计算量,尤其适用于长序列、高分辨率数据的处理,解决了传统自注意力O(n²)复杂度导致的效率瓶颈。
4.适配性广:可灵活适配具有层级结构的各类数据,无论是文本、图像、视频,还是跨模态数据,均可根据其天然层级设计对应的注意力结构,具有较强的通用性。
四、应用场景
层级注意力凭借其多尺度捕捉和可解释性优势,广泛应用于自然语言处理(NLP)、计算机视觉(CV)、跨模态处理等领域,典型应用场景如下:
1.自然语言处理(NLP)
○文本分类/情感分析:如HAN用于文档分类、Yelp评论情感评级,通过词级和句级注意力,精准捕捉情感倾向关键词和关键句子;
○长文本处理:如电商商品短标题生成,通过词级和句子级注意力,从数千字的商品详情中提取关键属性(如“90%白鸭绒”“-30℃抗寒”),生成精准简洁的标题;
○多语言处理:多语言分层注意力网络通过共享编码器和注意力机制,实现跨语言文档的语义理解和分类;
○长上下文语言建模:通过分层分解和特征聚合,扩展大语言模型的上下文窗口,提升对长文档、代码的理解能力。
2.计算机视觉(CV)
○图像分类/语义分割:如HAT-Net(基于分层注意力的视觉Transformer),通过像素块级局部注意力和合并后的全局注意力,兼顾细粒度细节和全局依赖,提升分类和分割精度;
○目标检测:通过分层注意力聚焦图像中的关键区域,抑制背景干扰,提升目标检测的准确性;
○视频分析:对视频的帧、片段、整体进行分层注意力计算,捕捉视频中的动作序列和场景变化,用于行为识别等任务。
3.跨模态处理:如电商跨模态场景中,融合文本(商品详情)和图像(商品图片)的分层注意力,实现更精准的商品推荐和标题生成。
五、优缺点分析
1.优点
•有效捕捉多尺度信息:既能关注底层细粒度细节,又能兼顾上层全局上下文,提升模型对复杂结构化数据的理解能力;
•减少信息损失:避免将所有信息压缩到单一表示中,通过分层聚合保留各层级的关键信息,提升特征表示的完整性;
•可解释性突出:注意力权重可视化可清晰展示模型决策依据,便于模型调试和结果分析;
•适配长序列/高维度数据:通过分层拆解降低计算复杂度,解决传统注意力处理长序列时效率低下的问题。
2.缺点
•模型结构复杂:相比普通注意力,需要设计多层级的编码器和注意力层,训练难度更高,对算力有一定要求;
•层级设计依赖数据特性:需要根据数据的天然层级定制注意力结构,缺乏通用的标准化设计方案,适配不同数据时需重新调整层级划分;
•存在梯度消失风险:多层级的循环编码(如GRU)可能导致梯度传递过程中衰减,影响模型训练效果,需通过优化器调整、残差连接等方式缓解。
六、技术演进与发展方向
层级注意力自提出以来,围绕“效率提升、性能优化、场景拓展”不断演进,当前主要发展方向包括:
1.效率优化:通过游戏理论、凸优化等方法,优化层级注意力的特征聚合策略,在保证性能的前提下,大幅降低计算成本,例如MAHA(多尺度聚合层级注意力)可将长序列处理的计算成本降低81%;
2.长上下文适配:通过分层构建-整合(如HiCI)等方法,扩展大语言模型的上下文窗口,实现对超长序列(如100k tokens)的有效处理,提升长文档、代码理解的性能;
3.跨模态融合:将分层注意力应用于多模态数据(文本、图像、音频),设计跨层级、跨模态的注意力机制,实现多源信息的高效融合,适配更多复杂场景;
4.参数高效化:通过参数共享、知识蒸馏等技术,压缩层级注意力模型的参数规模,实现轻量化部署,例如HiCI仅需增加5.5%的参数,即可大幅扩展模型上下文窗口;
5.结合其他机制:与多任务学习、知识图谱等结合,例如阿里云将层级注意力与多任务学习协同,通过任务感知的注意力门控,动态调整不同任务的注意力分布,提升模型的通用性和性能。
七、总结
层级/分层注意力是对传统注意力机制的重要升级,其核心价值在于通过“分层建模”,实现对结构化数据多尺度信息的精准捕捉,同时兼顾模型的可解释性和效率。它模拟人类注意力的分层分配逻辑,解决了传统注意力在长序列、高维度数据处理中存在的信息丢失、复杂度过高、可解释性差等问题,在NLP、CV、跨模态处理等领域具有不可替代的优势。
随着技术的不断演进,层级注意力正朝着更高效、更灵活、更通用的方向发展,通过与优化理论、多任务学习、知识蒸馏等技术的融合,将进一步突破现有瓶颈,为下一代大语言模型、计算机视觉模型提供更强大的注意力解决方案,赋能更多复杂的人工智能任务。