联邦学习(Federated Learning)与深度学习(Deep Learning)的结合,是当前人工智能领域的研究热点之一。这种结合既发挥了深度学习在复杂数据建模中的强大能力,又通过联邦学习的分布式框架解决了数据隐私、安全和合规问题,尤其适用于医疗、金融、物联网等数据敏感场景。
一、联邦学习与深度学习的技术融合
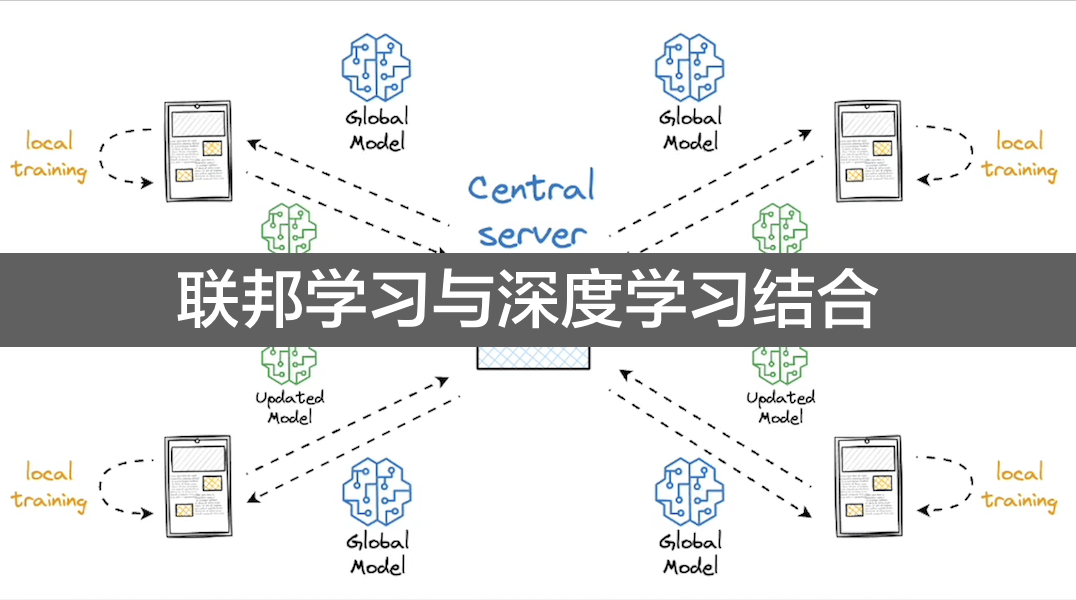
1.联邦深度学习的核心架构
联邦学习为深度学习提供了分布式训练框架,其核心流程如下:
初始化全局模型:服务器生成深度学习模型(如CNN、RNN、Transformer等)的初始参数。
客户端本地训练:各客户端基于本地数据对深度学习模型进行训练,计算梯度或更新后的参数。
服务器聚合更新:服务器收集客户端的模型更新,通过加权平均等策略聚合生成新的全局模型。
迭代优化:重复上述过程,直至模型收敛。
关键技术点:
异构数据处理:深度学习模型需适应客户端数据分布差异(NonIID),可通过数据增强、模型正则化(如FedProx)或元学习(MetaFederated Learning)优化。
通信效率:深度学习模型参数量大,需结合模型压缩(如梯度稀疏化、量化)、知识蒸馏(FedKD)或分层聚合减少传输成本。
隐私保护:结合差分隐私(Differential Privacy)、同态加密(Homomorphic Encryption)等技术,确保梯度传输安全。
2.典型算法与变体
FedSGD/ FedAvg + 深度学习模型
基础联邦学习算法与CNN、LSTM等模型结合,适用于图像分类、自然语言处理(NLP)等任务。例如:
在图像领域,使用FedAvg训练ResNet模型,各客户端基于本地医疗影像数据优化肿瘤检测模型,无需共享患者图像。
在NLP领域,通过FedSGD训练BERT模型,各客户端利用本地聊天记录优化智能客服系统,保护用户对话隐私。
联邦迁移学习(Federated Transfer Learning)
当客户端数据分布差异较大时,结合迁移学习(如预训练模型微调)提升模型泛化能力。例如:
不同医院的病理数据分布差异显著,通过联邦迁移学习,利用源域(数据丰富医院)的预训练模型,在目标域(数据稀缺医院)进行微调,减少训练样本需求。
联邦强化学习(Federated Reinforcement Learning, FRL)
将联邦学习与强化学习(RL)结合,适用于多智能体协作场景。例如:
自动驾驶中,多辆车通过联邦学习共享驾驶策略的梯度更新,协同优化RL模型,同时避免共享实时路况数据。
二、典型应用场景
1.医疗健康
场景:多中心联合训练医学影像诊断模型(如X光、CT扫描)。
优势:各医院使用本地脱敏数据训练深度学习模型(如3D CNN),服务器聚合模型更新,避免患者隐私泄露。
案例:美国斯坦福大学与多家医院合作,利用联邦学习训练糖尿病视网膜病变检测模型,在保护数据隐私的同时提升模型泛化能力。
2.金融科技
场景:银行联合训练反欺诈深度学习模型(如LSTM、图神经网络GNN)。
优势:各银行基于本地交易数据训练模型,共享梯度更新以识别跨机构欺诈模式,符合《个人信息保护法》要求。
案例:微众银行开源的联邦学习框架FATE,已应用于金融领域的联邦深度学习,支持风控模型联合训练。
3.智能终端与物联网
场景:手机端联合训练个性化推荐模型(如Transformerbased推荐系统)。
优势:用户行为数据(如浏览记录、搜索词)保留在本地,仅上传模型更新,减少隐私风险。
案例:Google的Gboard输入法通过联邦学习训练字符预测模型,提升输入体验的同时保护用户输入隐私。
4.工业与边缘计算
场景:分布式传感器数据训练设备故障预测模型(如CNNLSTM混合模型)。
优势:工厂各生产线设备基于本地时序数据训练模型,服务器聚合后优化全局故障预警策略,避免工业数据泄露。
三、关键挑战与解决方案
1.通信与计算开销
挑战:深度学习模型参数多(如BERT有亿级参数),每次迭代通信成本高,边缘设备(如手机、传感器)计算能力有限。
解决方案:
模型压缩:对梯度进行稀疏化(仅传输重要权重更新)或量化(降低数值精度)。
本地训练优化:客户端进行多轮本地迭代(如FedAvg),减少通信频率;利用模型蒸馏(FedKD)传输轻量级模型更新。
分层聚合:将客户端分组,组内先聚合再上传至中央服务器,减少通信节点数量。
2.数据异构性(NonIID)
挑战:客户端数据分布差异大,导致全局模型收敛慢、性能下降(如某客户端数据集中于少数类别)。
解决方案:
数据预处理:通过数据增强(如旋转、裁剪)或迁移学习平衡数据分布。
算法改进:使用FedProx(引入近端项约束客户端模型更新)、FedNova(标准化本地更新)等算法缓解异构性影响。
元学习初始化:通过元学习生成更适应异构数据的全局模型初始化参数(如FedMeta)。
3.隐私与安全风险
挑战:梯度传输可能泄露数据特征(如通过梯度反推原始图像),联邦学习系统面临模型投毒、拜占庭攻击等安全威胁。
解决方案:
隐私增强技术:
差分隐私(DP):在梯度中添加噪声,确保单个数据样本不影响全局模型。
同态加密(HE):对梯度进行加密传输,服务器在密文下完成聚合(如ABY3框架)。
安全聚合协议:采用多方安全计算(MPC)确保梯度聚合过程中无单点泄露,如Secure MultiParty Aggregation(SMPA)。
对抗鲁棒性:通过鲁棒优化(Robust Optimization)或异常检测过滤恶意客户端的更新。
4.系统异构性
挑战:客户端设备性能差异大(如手机 vs. 服务器),部分设备可能随时退出训练,导致系统不稳定。
解决方案:
动态参与策略:允许客户端非同步参与训练(如FedAsync),服务器忽略超时或离线设备的更新。
自适应资源分配:根据设备计算能力动态调整本地训练轮数或分配数据量。
四、开源框架与工具
1.FATE:由微众银行开源,支持多方安全计算、差分隐私等技术,在金融场景中落地成熟,可支持CNN、RNN、GNN等模型。
2.TensorFlow Federated (TFF)**:由Google开发,深度集成TensorFlow生态,适合用于研究与原型开发,支持Keras模型(如CNN、Transformer等)。
3.PySyft:基于PyTorch框架,侧重隐私保护与差分隐私技术,支持联邦学习与迁移学习结合,可应用于PyTorch模型(如LSTM、GAN等)。
4.FedML:具备跨框架特性(支持PyTorch/TensorFlow),可处理异构数据并适配边缘设备,提供丰富的算法库,支持深度学习模型与强化学习模型。
5.OpenMined:由社区驱动,聚焦隐私保护的机器学习领域,集成PySyft和差分隐私工具,可支持各类深度学习模型。
五、未来发展方向
1.自动化联邦学习:结合AutoML技术,自动优化联邦学习参数(如客户端选择、学习率调度),降低使用门槛。
2.联邦多模态学习:融合图像、文本、语音等多模态数据的联邦训练,拓展至更复杂场景(如跨平台推荐系统)。
3.边缘智能与联邦学习结合:在边缘节点(如基站、网关)部署轻量化深度学习模型,减少对中央服务器的依赖,提升实时性。
4.联邦学习与区块链结合:利用区块链的去中心化特性实现安全可信的客户端身份认证和模型更新溯源,防止恶意攻击。
结言
联邦学习与深度学习的结合,为数据敏感场景下的AI应用提供了可行路径。通过分布式训练框架与隐私保护技术,该技术既能发挥深度学习的强大建模能力,又能满足数据合规要求。尽管面临通信开销、数据异构性等挑战,随着算法优化、硬件升级和开源工具的成熟,联邦深度学习有望在医疗、金融、物联网等领域实现大规模落地,推动“数据可用不可见”的AI新范式。