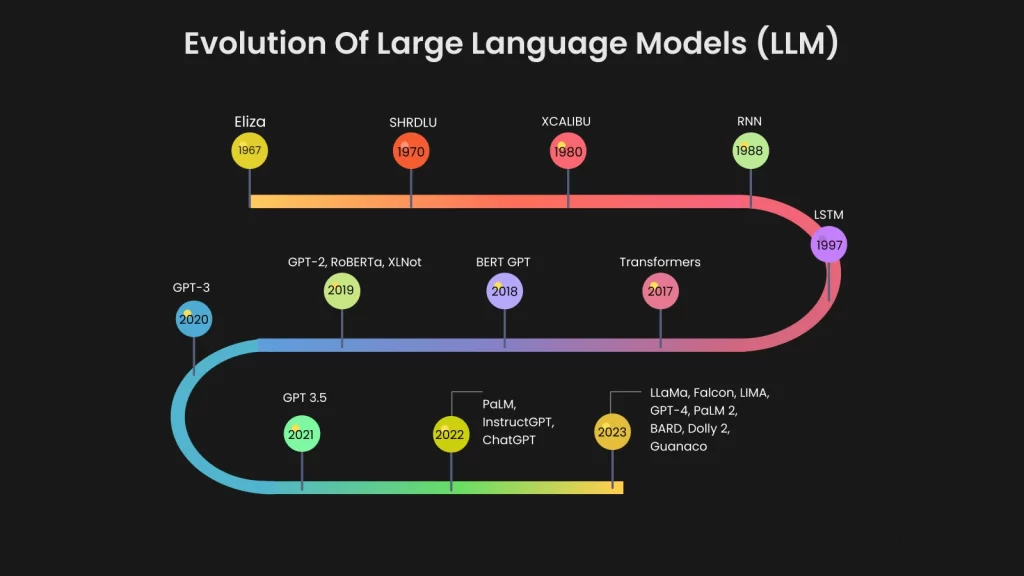
在数字化时代浪潮的推动下,自然语言处理(NLP)领域正经历着前所未有的变革,其中大语言模型(Large Language Models, LLMs)无疑是最为耀眼的明星。近年来,大语言模型取得了令人瞩目的显著进展,宛如一颗在技术苍穹中冉冉升起的新星,迅速照亮了自然语言处理的诸多应用场景。这些模型展现出了令人惊叹的能力,它们能够生成逻辑连贯、语法正确且富有语义内涵的高质量文本,无论是撰写新闻报道、创作故事小说,还是生成专业领域的文档,都能应对自如;在对话场景中,它们能进行复杂且流畅的交互,理解用户的意图,提供准确而恰当的回应,宛如一位知识渊博、沟通无碍的交流伙伴;在语言翻译方面,大语言模型跨越了不同语言之间的壁垒,实现了多种语言之间的精准转换,极大地促进了全球范围内的信息交流与文化传播。更为惊人的是,在诸多自然语言处理任务中,大语言模型的表现已经接近甚至在某些特定方面超越了人类水平,这一突破性的进展引发了学术界、产业界乃至全社会的广泛关注与深入探讨。
一、语言模型的起源与早期发展
1.统计语言模型
语言模型的溯源可回溯至20世纪50年代,那时,基于统计方法的语言模型如一颗微弱的火种,在技术的荒原中悄然燃起。这类模型的核心运作机制是通过计算词序列的概率,以此来预测下一个可能出现的词。其中,n - gram模型堪称这一时期的经典代表,它如同一位遵循简单规则的工匠,通过统计前n - 1个词的组合情况,来对第n个词进行预测。例如,在一个三元组(“我”,“喜欢”,“苹果”)构成的n - gram模型中,当看到“我”和“喜欢”这两个词时,模型会根据过往统计数据,给出在该语境下“苹果”或其他可能词汇出现的概率。
然而,n - gram模型这一早期语言模型的代表,虽在特定场景下展现出一定的有效性,却也暴露出两个极为显著的问题。其一,数据稀疏性问题犹如一座难以逾越的高山横亘在前。随着上下文窗口的不断增大,模型所需要处理的词组合数量呈现出指数级增长的态势。这就好比在一个不断扩张的词汇宇宙中,模型要去记忆和处理的星球数量以惊人的速度增加,导致数据的存储和计算成本急剧上升,同时也使得模型在面对一些低频或罕见的词组合时,因缺乏足够的数据支持而无法准确预测。其二,n - gram模型在语义理解方面宛如一个懵懂的孩童,无法捕捉词与词之间深层次的语义关系。它只是简单地基于词的共现频率进行计算,而对于词汇背后丰富的语义内涵、词与词之间的逻辑关联,如“苹果”作为水果与“苹果”公司品牌之间的语义差异,以及“购买”与“商品”之间的逻辑联系等,n - gram模型则显得力不从心。
2.神经网络语言模型
时光的指针拨至21世纪初,神经网络技术犹如一股强劲的春风,为语言模型的发展带来了全新的生机与可能性。2003年,Bengio等人宛如智慧的开拓者,提出了首个基于神经网络的语言模型——神经概率语言模型(Neural Probabilistic Language Model, NPLM)。该模型创新性地使用嵌入层,将词汇巧妙地映射到连续向量空间,这一过程就像是为每个词汇在一个多维的语义空间中找到了属于自己的独特坐标。例如,“猫”和“狗”这两个在语义上相近的词汇,在向量空间中的位置也会较为接近。而后,通过多层感知机(MLP)对这些向量进行复杂的计算,从而得到词的概率分布。这种方法犹如为语言模型赋予了一种更为智能的“理解”能力,有效地解决了传统n - gram模型所面临的数据稀疏性难题。
然而,技术的发展总是伴随着挑战,NPLM在训练效率方面遭遇了严重的瓶颈。由于其复杂的神经网络结构和大规模的参数计算,模型的训练过程犹如一辆在泥泞道路上艰难前行的重型卡车,速度极为缓慢,需要耗费大量的计算资源和时间成本。这一问题在一定程度上限制了NPLM的广泛应用与进一步发展,也促使研究者们不断探索新的技术路径,以推动语言模型向更高性能的方向迈进。
二、深度学习驱动的语言模型革命
1.循环神经网络(RNN)与长短期记忆网络(LSTM)
2010年代初期,循环神经网络(Recurrent Neural Networks, RNN)如同一颗闪亮的新星,在语言建模的天空中崭露头角,迅速成为该领域的主流方法。RNN的核心设计理念充满了智慧的光芒,它通过隐藏状态来捕捉序列中的时间依赖关系,就像是一位拥有记忆的旅行者,在语言的时间长河中前行时,能够记住之前的经历,并根据这些记忆来处理当前遇到的信息。例如,在处理一个句子“我昨天去了公园,今天感觉很愉快”时,RNN能够利用从“昨天”到“今天”的时间序列信息,理解句子中前后事件的关联。
然而,标准RNN在实际应用中并非一帆风顺,当面对长序列信息时,它就像是一个记忆力有限的人,容易出现梯度消失或梯度爆炸问题。在梯度消失的情况下,随着序列的不断推进,模型对于早期信息的记忆会逐渐模糊,导致在处理长文本时,无法有效地利用开头部分的重要信息;而梯度爆炸则如同失控的火箭,使得模型的参数更新变得异常剧烈,导致模型无法稳定训练。
为了攻克这一难关,1997年,Hochreiter和Schmidhuber如同勇敢的探索者,提出了长短期记忆网络(Long Short - Term Memory, LSTM)。LSTM引入了精妙的门控机制,这一机制就像是为模型的记忆系统安装了智能开关,能够精准地控制信息的流动。通过输入门、遗忘门和输出门的协同工作,LSTM能够有选择地保留或丢弃信息,从而更好地捕捉长距离依赖关系。在实际应用中,LSTM在机器翻译、文本生成等任务中表现出色,例如在机器翻译中,它能够准确地处理源语言句子中的长序列信息,将其准确地翻译成目标语言,大大提高了翻译的质量和准确性。然而,LSTM并非完美无缺,其训练速度相对较慢的问题,在一定程度上限制了它在大规模数据处理和实时应用场景中的应用。
2.注意力机制与Transformer架构
2017年,Vaswani等人宛如技术领域的革新者,提出了一种具有革命性意义的全新架构——Transformer,这一架构的诞生彻底改变了语言建模的发展轨迹,犹如一场突如其来的风暴,席卷了整个自然语言处理领域。Transformer的核心创新点在于巧妙地利用自注意力机制(Self - Attention Mechanism),这种机制使得模型能够像一位拥有全局视野的观察者,轻松捕捉输入序列中任意位置之间的关系,而不再依赖传统的递归结构。
与RNN和LSTM相比,Transformer具有诸多显著优势。首先,在训练效率方面,由于其不依赖序列顺序进行计算,Transformer能够充分发挥GPU强大的并行计算能力,就像是一支训练有素的军队,各个士兵能够同时开展工作,大大缩短了模型的训练时间。其次,在上下文建模能力上,自注意力机制赋予模型全局上下文建模的能力,使其能够同时关注整个输入序列的所有信息,避免了长距离依赖问题的困扰。例如,在处理一篇长文章时,Transformer能够瞬间把握文章中各个段落、句子之间的关联,而不像RNN和LSTM那样容易在长序列中迷失方向。
Transformer架构的横空出世,标志着语言模型的发展进入了一个全新的时代,它为后续大语言模型的蓬勃发展奠定了坚实的基础,成为了现代自然语言处理技术的基石。自Transformer诞生以来,众多基于其架构的优秀模型如雨后春笋般涌现,不断推动着自然语言处理技术向更高水平迈进。
三、大语言模型的崛起
1.GPT系列:生成式预训练模型
2018年,OpenAI如同技术领域的先锋,推出了基于Transformer架构的生成式预训练模型(Generative Pre - trained Transformer, GPT),这一模型的问世犹如一颗投入平静湖面的巨石,激起了层层涟漪。GPT采用了一种创新的训练模式,即通过在海量的无监督数据上进行预训练,让模型学习到语言的通用模式和语义知识,然后在下游的各种特定任务中进行微调。这种训练方式赋予了GPT强大的泛化能力,使其能够快速适应不同的自然语言处理任务,就像是一位多才多艺的演员,能够轻松驾驭各种不同类型的角色。
随后,OpenAI又相继发布了GPT - 2和GPT - 3,这两款模型在规模上进一步实现了巨大的跨越,参数量分别飙升至15亿和1750亿。这种规模上的急剧扩张使得模型的能力得到了质的飞跃,GPT - 3的发布更是引发了全球范围内的广泛关注与热烈讨论。在零样本(zero - shot)和少样本(few - shot)学习场景中,GPT - 3展现出了令人惊叹的表现,它能够在几乎没有见过特定任务示例的情况下,凭借其在大规模预训练中学习到的知识,对任务进行准确的理解和处理,生成高质量的文本输出,这一能力的突破为自然语言处理技术的应用开辟了全新的可能性。
2.BERT系列:双向编码器表示
几乎在同一时期,Google作为技术领域的重要力量,也在积极探索语言模型的创新之路,提出了另一种基于Transformer架构的强大模型——BERT(Bidirectional Encoder Representations from Transformers)。BERT的独特创新之处在于采用了双向编码方式,与传统的单向语言模型不同,BERT能够同时考虑上下文的左右两侧信息,就像是一位既能向前看又能向后看的观察者,全面地理解文本的语义。
这种创新的设计使得BERT在问答、句子分类等自然语言处理任务中表现得尤为出色。例如,在问答任务中,BERT能够综合问题和文本中的前后文信息,准确地定位答案所在位置,给出精准的回答;在句子分类任务中,它能够充分理解句子的整体语义,将句子准确地归类到相应的类别中。BERT的巨大成功如同一个强大的催化剂,激发了学术界和产业界的创新热情,推动了大量基于BERT的改进模型如RoBERTa、ALBERT和ELECTRA等的相继出现,这些模型在不同的应用场景中不断优化和拓展BERT的能力,进一步丰富了自然语言处理技术的生态系统。
3.多模态与跨领域融合
近年来,大语言模型的发展呈现出一种新的趋势,即逐渐向多模态方向拓展。传统的大语言模型主要专注于处理文本数据,而如今的模型已经开始具备处理文本以外其他数据类型的能力,如图像、音频和视频等。这种多模态融合的能力就像是为模型赋予了多双不同的眼睛和耳朵,使其能够从多种信息源中获取知识,从而在更广泛、更复杂的场景中得以应用。
以OpenAI的CLIP模型为例,它通过联合训练文本和图像数据,实现了跨模态的语义理解。这意味着CLIP能够理解文本描述与图像之间的语义关联,例如当输入“一只猫在草地上玩耍”这样的文本时,CLIP能够准确地识别出与之对应的图像,反之亦然。而DALL·E则更进一步,将语言生成与图像生成巧妙地相结合,用户只需输入一段自然语言描述,如“一座由巧克力建成的城堡”,DALL·E就能根据这一描述生成高质量的图像,这种神奇的能力为创意设计、艺术创作等领域带来了全新的灵感和可能性。
类似地,Google的MUM(Multitask Unified Model)也展现出了强大的跨领域适应能力。它不仅能够支持多种语言之间的流畅翻译,打破语言之间的交流障碍,还能够处理文本、图像等多种输入形式。例如,用户可以向MUM提出一个关于某个历史事件的问题,并同时提供一张相关的图片,MUM能够综合分析这些信息,给出全面而准确的回答,这种跨领域的处理能力使得MUM在智能搜索、知识问答等领域具有巨大的应用潜力。
此外,跨领域的大规模预训练也为模型的泛化能力提供了新的突破方向。通过在大量多样化的数据集上进行预训练,这些模型能够学习到更加通用、广泛的特征表示,从而在未见过的任务或领域中也能表现出优异的性能。例如,Meta的OPT和BigScience的BLOOM等开源模型,不仅拥有庞大的参数量,涵盖了多种语言和任务类型,为全球范围内的研究者和开发者提供了丰富而宝贵的资源,推动了大语言模型技术在不同领域的广泛应用和创新发展。
四、关键技术突破与优化策略
1.模型规模与计算效率的平衡
随着大语言模型规模如火箭般不断攀升,模型的性能得到了显著提升,但与此同时,计算成本也如同天文数字般急剧增长,如何在这两者之间找到一个完美的平衡点,成为了摆在研究者面前的一道关键难题。为了应对这一挑战,研究人员宛如智慧的工匠,提出了多种精妙的优化策略。
稀疏激活技术便是其中的一大创新。MoE(Mixture of Experts)架构作为稀疏激活的典型代表,其运作方式犹如一个分工明确的团队。在这个架构中,模型由多个专家网络组成,在推理过程中,它能够根据输入数据的特点,动态地选择部分专家网络参与计算,而不是让所有的网络都进行运算。这就好比在一个大型工厂中,根据不同的生产任务,灵活地安排相应的车间和工人进行工作,避免了资源的浪费。以Switch Transformer和GLaM等模型为例,它们采用了类似的MoE架构,在保持高精度的同时,显著降低了推理时的计算开销,极大地提高了计算资源的利用效率,为大规模模型在实际应用中的部署提供了可行的方案。
量化与剪枝技术则从另一个角度对模型进行优化。通过对模型权重进行低精度量化,即将原本高精度的权重值用较低精度的数值表示,就像是用更简洁的语言来表达相同的意思,在一定程度上减少了数据存储和计算的需求。同时,剪枝技术则如同一位园艺师修剪树枝一样,移除模型中冗余的参数,去除那些对模型性能贡献较小的部分。这种双管齐下的方法能够有效地压缩模型体积,加速推理过程,尤其在资源受限的设备上,如移动终端、嵌入式设备等,具有重要的实际应用价值,使得大语言模型能够更加便捷地服务于更广泛的用户群体。
2.预训练与微调范式的演进
传统的预训练 - 微调范式在大语言模型的发展历程中发挥了重要作用,它为模型在不同任务上的应用提供了一种有效的途径。然而,随着技术的不断发展和应用场景的日益复杂,这种范式在面对特定任务时逐渐显露出一些局限性。
近年来,“指令微调”(Instruction Tuning)和“提示工程”(Prompt Engineering)如同两颗冉冉升起的新星,逐渐在提升模型性能的舞台上崭露头角,成为大语言模型技术发展的重要方向。指令微调通过在多样化的指令数据集上对模型进行额外的训练,就像是为模型提供了一本详细的任务指南,使其能够更好地理解和执行用户提供的各种任务描述。这种训练方式极大地增强了模型在零样本和少样本场景中的表现,让模型能够在没有大量特定任务示例的情况下,依然能够准确地理解用户意图并给出高质量的回答。
提示工程则是一种更加巧妙的优化手段,它通过精心设计合适的输入模板或上下文信息,就像是为模型搭建了一座通向正确答案的桥梁,引导模型生成符合预期的输出。与传统方法不同的是,提示工程无需对模型结构进行复杂的修改,仅仅依赖于输入的构造方式,就能实现模型性能的显著提升。例如,在文本生成任务中,通过设计一个富有启发性的提示,如“以春天的花园为背景,创作一首优美的诗歌”,模型能够根据这个提示生成更加符合要求的诗歌作品,这种灵活性和高效性使得提示工程在实际应用中具有广泛的应用前景。
3.可解释性与可控性
尽管大语言模型在自然语言处理的众多任务中展现出了卓越的性能,如同一位技艺高超的大师,能够轻松应对各种复杂的任务,但它们的内部工作机制却常常被视为一个难以捉摸的“黑箱”,缺乏足够的透明性和可解释性。这就好比我们拥有一辆性能卓越的汽车,但却对其引擎内部的工作原理一无所知,这种不确定性在一定程度上影响了人们对模型的信任和应用。
为了揭开这个“黑箱”的神秘面纱,提高模型的可信度,研究人员们宛如一群勇敢的探险家,正在积极探索多个方向。注意力可视化技术为我们提供了一种窥探模型内部工作的窗口,通过深入分析自注意力机制的权重分布,我们能够清晰地看到模型在处理输入时关注的重点区域。例如,在分析一段新闻报道时,我们可以通过注意力可视化了解模型在理解句子时,对哪些词汇或短语给予了更多的关注,从而推断模型的理解逻辑。
知识蒸馏技术则像是将一杯浓郁的咖啡浓缩成精华,它将复杂的大模型所蕴含的知识迁移到小型模型中。在这个过程中,小型模型在保留大模型核心功能的同时,其结构更加简单,可解释性也得到了显著提升。这不仅有助于我们更好地理解模型的工作原理,还能够在一些资源受限的场景中,使用小型模型实现类似大模型的核心功能同时提升可解释性。
在伦理约束方面,引入规则或奖励机制,确保模型生成的内容符合社会规范和道德标准。
五、未来发展方向与挑战
1.更高效的模型架构
当前的大语言模型虽然取得了显著成果,但其庞大的参数量和高昂的训练成本仍然是制约因素。未来的模型架构可能会朝着更高效的方向发展,例如:
● 模块化设计:构建灵活的组件化架构,使模型能够根据不同任务需求动态调整自身结构。
● 自监督学习的创新:开发新的自监督目标函数,进一步挖掘无标注数据中的潜在信息。
2.多语言与文化包容性
尽管现有模型已经具备一定的多语言处理能力,但在低资源语言和方言的支持上仍有不足。未来的研究需要更多地关注语言多样性,确保技术成果惠及全球各个地区和群体。
3.安全性与隐私保护
随着大语言模型在敏感领域的应用日益广泛,其安全性和隐私保护问题也愈发凸显。如何防止模型泄露个人隐私、生成有害内容或被恶意利用,是亟待解决的重要课题。可能的解决方案包括:
● 差分隐私:在训练过程中加入噪声,以保护个体数据的隐私。
● 对抗性防御:增强模型对恶意攻击的抵抗力,避免生成误导性或危险的内容。
4.人机协作新模式
最后,大语言模型的发展有望推动人机协作进入新阶段。从辅助创作到智能决策支持,这些模型将成为人类认知能力的重要补充。然而,如何设计友好的交互界面、建立信任关系,以及明确人类与机器的责任边界,仍是值得深入探讨的问题。