图像标注在多个领域有着广泛应用。在计算机视觉研究方面,它为各种计算机视觉算法的训练和评估提供数据支持,助力研究人员开发更先进的图像识别与理解算法;在自动驾驶领域,通过标注道路场景图像中的车辆、行人、交通标志、车道线等,让自动驾驶系统得以准确感知周围环境并做出决策;安防监控中,对监控视频里的人物、物体等进行标注,能够实现行为分析、目标追踪等功能,提升安防监控的智能化水平;医疗影像分析时,标注医学影像中的病变区域、器官等,可辅助医生进行疾病诊断与分析,提高诊断的准确性和效率。
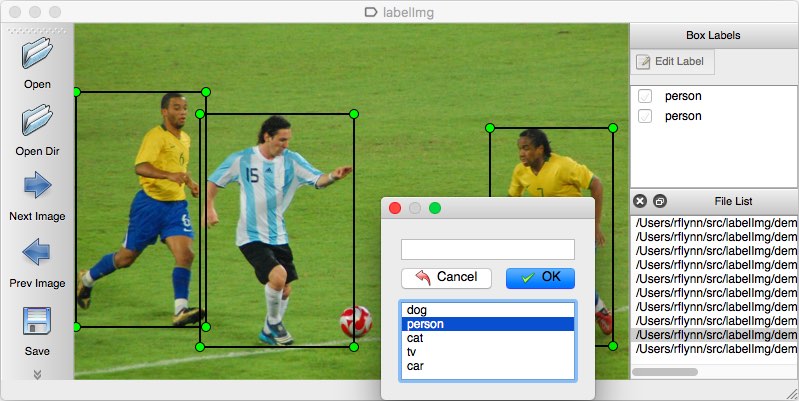
LabelImg是一款专门用于图像标注的工具,支持矩形框、多边形等多种标注方式,可用于目标检测、图像分割等任务的数据标注,输出格式通常为PASCAL VOC或YOLO格式,简单易用,界面直观。
项目地址:https://github.com/HumanSignal/labelImg
一、图像标注
图像标注是一种为图像添加标签或注释的技术手段,目的是使计算机能够更好地理解和处理图像内容。
1.图像标注的类型
分类标注:这是较为简单的一种标注类型,就是给整幅图像赋予一个特定的类别标签,比如将一张图片标注为“风景”“人物”“动物”等。这种标注方式主要用于图像分类任务,让计算机学习不同类别图像的特征,以便对新的图像进行分类识别。
目标检测标注:需要在图像中找出特定目标物体的位置,并使用矩形框、圆形框等将其框选出来,同时为每个目标物体标注上对应的类别,如在一张城市街道的图片中,用矩形框出汽车、行人、路灯等物体,并分别标注为“汽车”“行人”“路灯”。这对于计算机视觉中的目标检测任务至关重要,能帮助计算机定位和识别图像中的多个不同目标。
语义分割标注:是将图像中的每个像素都进行分类标注,使计算机能够理解图像中每个区域的语义信息。比如将一幅自然场景图像中的天空、草地、树木、建筑物等不同区域的每个像素都标注为对应的类别,从而实现对图像内容的精细理解,常用于图像编辑、自动驾驶场景感知等领域。
实例分割标注:不仅要对图像中的每个像素进行分类,还要将属于同一物体实例的像素区分开来。例如在一张有多个苹果的图片中,需要将每个苹果的像素都准确标注出来,区分不同的苹果实例,这在一些需要精确识别和区分多个相似物体的场景中非常重要。
2.图像标注的方法
人工标注:由专业的标注人员通过图像标注工具,根据标注任务的要求,手动在图像上进行标注。这种方法标注精度高,但效率较低,成本较高,适用于对标注精度要求极高的场景,如医疗影像标注。
半自动标注:借助一些算法和工具,对图像进行初步的处理和标注,然后由人工进行审核和修正。例如利用图像分割算法对图像进行初步分割,标注人员只需对分割结果进行调整和添加标签,能在一定程度上提高标注效率,同时保证标注质量。
自动标注:利用机器学习、深度学习等技术,让计算机模型自动对图像进行标注。比如使用已经训练好的目标检测模型对大量图像进行初步标注,但自动标注的准确性通常有待提高,一般需要人工进一步校验和修正。
二、基本功能
1. 图像标注
目标框标注:LabelImg 最核心的功能是对图像中的目标物体进行矩形框标注。用户可以使用鼠标在图像上绘制矩形框,将需要识别的目标物体框选出来,并为每个框添加对应的类别标签。例如,在进行目标检测任务时,若要识别图像中的汽车、行人等,就可以用矩形框分别框出汽车和行人,并标注相应的类别。
多类别标注:支持对同一图像中的不同目标物体标注不同的类别。用户可以在标注过程中轻松切换类别,为不同的目标赋予特定的标签,方便后续模型训练时区分不同类型的目标。
2. 标注管理
标注文件保存:能够将标注信息保存为特定格式的文件,常见的保存格式有 PASCAL VOC 格式(XML 文件)和 YOLO 格式(TXT 文件)。这些文件记录了每个目标框的位置(坐标信息)和对应的类别标签,方便后续的模型训练使用。
标注文件加载:可以加载之前保存的标注文件,用户能够继续对未完成的标注任务进行编辑,或者对已标注的图像进行修改和调整。
3. 图像浏览
图像切换:支持在多个图像之间进行快速切换浏览,方便用户对批量图像进行连续标注。用户可以通过简单的操作(如使用快捷键或点击按钮)在不同图像之间跳转,提高标注效率。
三、技术特点
1. 开源免费:LabelImg 是开源软件,用户可以自由下载和使用,并且可以根据自己的需求对源代码进行修改和扩展。这使得它在学术界和工业界都得到了广泛的应用,降低了使用成本。
2. 跨平台支持:该工具可以在多种操作系统上运行,包括 Windows、Linux 和 macOS。这意味着不同操作系统的用户都可以方便地使用 LabelImg 进行图像标注工作,具有很好的通用性。
3. 操作简单:具有直观的图形用户界面(GUI),即使是没有编程经验的用户也能快速上手。用户只需要通过鼠标和键盘的简单操作,就可以完成图像标注、标签添加等任务,大大提高了标注效率。
四、不足之处
1. 标注类型有限:主要支持矩形框标注,对于一些复杂的标注需求,如多边形标注、语义分割标注等,LabelImg 无法满足。在处理不规则形状的目标物体时,矩形框标注可能无法准确地描述目标的边界,从而影响后续模型的训练效果。
2. 缺乏协同标注功能:不支持多人同时对同一组图像进行标注。在大规模的标注任务中,可能需要多个标注人员协同工作,而 LabelImg 无法提供这样的功能,限制了其在团队协作场景下的应用。
3. 性能问题:在处理大量高分辨率图像时,可能会出现性能下降的情况,如界面响应缓慢、加载时间过长等。这会影响标注效率,尤其是在标注大规模数据集时,问题会更加明显。
五、应用场景
1. 目标检测:在计算机视觉的目标检测任务中,需要大量带有标注信息的图像来训练模型。LabelImg 可以帮助用户快速准确地标注图像中的目标物体,为目标检测模型的训练提供数据支持。例如,在自动驾驶领域,需要识别道路上的车辆、行人、交通标志等,就可以使用 LabelImg 对相关图像进行标注。
2. 图像分类:虽然图像分类任务主要关注图像的整体类别,但在某些情况下,也需要对图像中的特定区域进行标注。例如,在医学图像分类中,可能需要标注出图像中的病变区域,以便更好地进行分类。LabelImg 可以用于对这些特定区域进行标注,辅助图像分类任务的完成。
3. 教学与科研:在计算机视觉相关的教学和科研工作中,需要进行图像标注实验来验证算法的有效性。LabelImg 由于其简单易用的特点,非常适合用于教学和科研中的图像标注任务,帮助学生和研究人员快速获取标注数据。