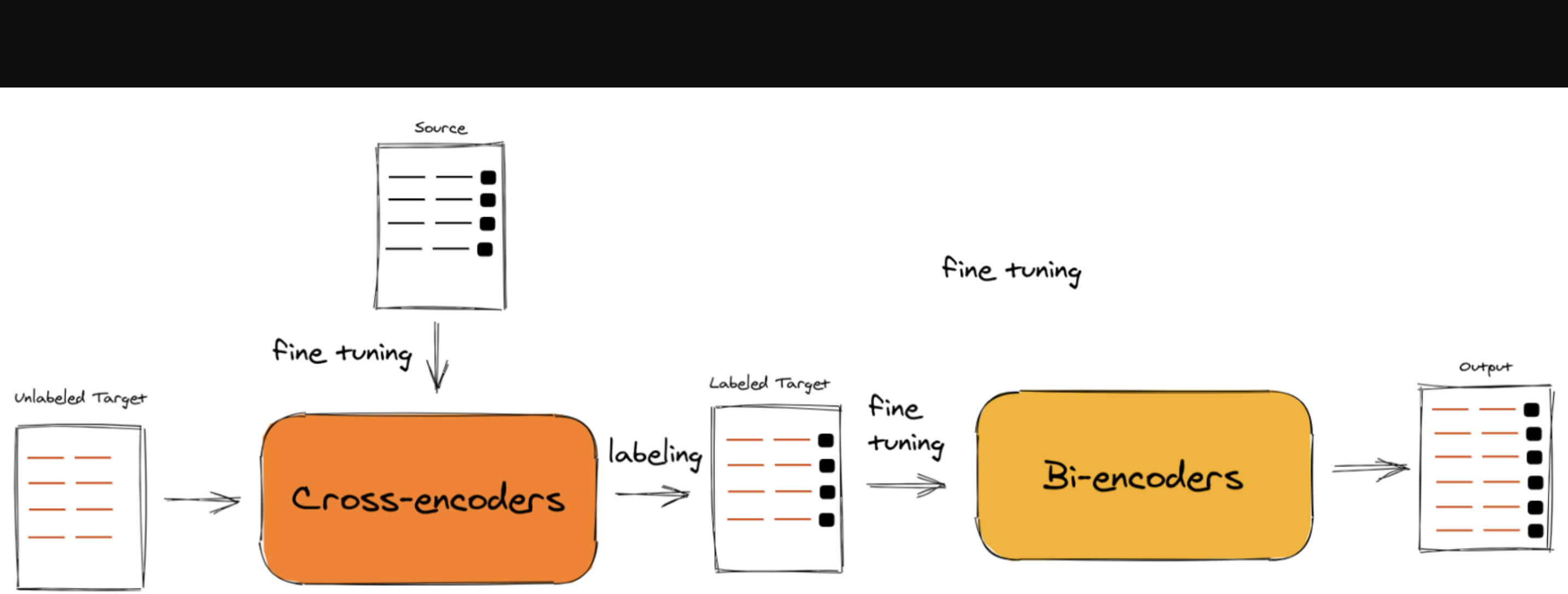
检索器是信息检索系统中的核心组件,其基本功能是根据用户输入的查询信息,从大量的数据集合中快速、准确地找到与之相关的信息资源。
一、双编码器检索器
bi-encoder检索器即双编码器检索器,是信息检索和自然语言处理领域中的一种重要工具,以下从其原理、结构、优势和应用场景等方面进行介绍:
1.基本原理
编码机制:bi-encoder检索器通常由两个编码器组成,一个用于对查询(query)进行编码,另一个用于对文档(document)进行编码。这两个编码器可以是基于深度学习的神经网络结构,如Transformer、BERT等。其核心原理是将查询和文档分别映射到一个低维向量空间中,使得在这个向量空间中,语义相似的查询和文档的向量表示距离较近,而语义不相关的则距离较远。
相似度计算:在将查询和文档都编码为向量后,通过计算这两个向量之间的相似度来衡量查询与文档的匹配程度。常用的相似度计算方法有余弦相似度、欧式距离等。例如,余弦相似度通过计算两个向量的夹角余弦值来判断它们的相似性,值越接近1,表示两个向量越相似,即查询和文档的语义越相关。
2.模型结构
查询编码器:负责对用户输入的查询进行处理和编码。它会对查询文本进行分词、嵌入表示等操作,然后通过多层神经网络对这些嵌入向量进行特征提取和语义建模,最终生成一个固定长度的查询向量表示。
文档编码器:与查询编码器类似,文档编码器用于对文档集合中的每个文档进行编码。它会逐一对文档进行处理,将文档中的文本转换为向量表示,并提取文档的语义特征,生成文档向量。
训练机制:在训练阶段,biencoder检索器通常使用大量的查询文档对作为训练数据。通过优化目标函数,如最大化正确匹配的查询文档对的相似度得分,最小化错误匹配的相似度得分,来调整两个编码器的参数,使得模型能够学习到有效的语义表示,从而提高检索的准确性。
二、交叉编码器检索器
cross-encoder:只有一个编码器,它将查询和文档作为一个整体输入进行编码。在编码过程中,通过注意力机制等技术,直接对查询和文档之间的交互信息进行深度建模,能够更充分地捕捉两者之间的语义关系和上下文信息,最后通过一个分类器或回归器等模块输出它们的匹配得分。
三、性能表现
1.双编码器检索器
优点:计算效率高,因为查询和文档的编码可以预先计算并存储,检索时只需计算向量间的相似度,无需重复处理文本,适合处理大规模数据,可扩展性强。由于两个编码器独立,能更好地捕捉查询和文档各自的语义信息,在一些需要精确匹配和快速检索的场景中表现出色,如搜索引擎中的快速文本检索。
缺点:可能在捕捉查询和文档之间的细粒度交互信息方面相对较弱,因为两个编码器是独立工作的,对于一些需要深入理解查询和文档之间复杂语义关系的任务,可能表现不如单编码器检索器。
2.交叉编码器检索器
优点:能够更准确地捕捉查询和文档之间的语义交互,在处理需要深入理解上下文和语义关联的任务时表现更好,例如在处理复杂的自然语言问题、语义蕴含判断等任务中,能够给出更准确的匹配得分和结果,在各种文本匹配任务中的准确率通常较高。
缺点:计算复杂度较高,每次处理都需要将查询和文档作为一个整体输入进行编码,处理速度相对较慢,在面对大规模数据和高并发查询时,性能可能会受到一定影响,推理速度较慢,不适用于对实时性要求极高的场景。
四、应用场景
1.双编码器检索器应用场景实例
搜索引擎:在如百度、谷歌等大型搜索引擎中,双编码器检索器可快速处理用户输入的查询和网页文档。预先将网页文档编码成向量存储,用户输入查询后,即时将查询编码为向量,通过计算向量相似度,能在海量网页中迅速找到相关度较高的网页,为用户提供快速的检索结果。
智能客服系统:在线购物、电信运营商等的智能客服系统中,双编码器检索器可以将常见问题和对应的答案文档分别编码。当用户提出问题时,快速将用户问题编码并与答案文档向量对比,快速找到最匹配的答案回复用户,提高客服效率,减轻人工客服压力。
视频检索系统:在视频网站或企业内部的视频管理系统中,对于视频内容的检索可以采用双编码器检索器。将视频的特征(如关键帧、音频特征等)和用户输入的文本查询分别编码,实现基于文本描述的视频检索,帮助用户快速找到感兴趣的视频。
推荐系统:音乐、新闻等推荐系统中,双编码器检索器把用户的行为数据、兴趣偏好等编码为用户向量,把音乐、新闻等内容编码为内容向量,通过计算向量相似度,为用户推荐可能感兴趣的音乐、新闻等内容,实现个性化推荐。
2.交叉编码器检索器应用场景实例
学术文献检索:在学术数据库中,用户输入复杂的研究问题或特定的学术术语,交叉编码器检索器能够准确理解查询内容与文献之间的语义关系,从海量学术文献中精准检索出与用户需求高度相关的文献,帮助研究人员快速获取有价值的研究资料。
法律文档检索:法律领域的文档通常具有高度的专业性和严谨性,交叉编码器检索器可以准确匹配法律条款、案例与用户的法律问题或检索需求,帮助法律工作者快速找到相关的法律依据和类似案例,为法律研究和案件处理提供支持。
医疗问答系统:在医疗健康领域,患者或医护人员提出关于疾病症状、诊断、治疗方案等问题时,交叉编码器检索器能够将问题与医学知识库中的内容进行精确匹配,找到最相关的答案,为用户提供准确的医疗信息。
通用知识问答:如智能语音助手等通用问答系统中,交叉编码器检索器可以理解用户自然语言提问的意图,从大规模的知识图谱或文本数据中检索出准确的答案,为用户提供各种知识类问题的解答。
文本相似度计算:用于判断两篇文本在语义上的相似程度,例如在论文查重系统中,交叉编码器检索器可以准确检测出论文之间的相似部分,帮助识别学术不端行为;在内容推荐系统中,也可根据文本相似度为用户推荐相似主题的文章、新闻等内容。
文本分类任务:将文本分类到不同的类别中,如新闻文本分类、情感分类等。交叉编码器检索器可以通过将待分类文本与各个类别标签的特征进行匹配,准确判断文本所属的类别,为文本的组织和管理提供支持。
个性化商品推荐:在电商平台中,交叉编码器检索器可以将用户的搜索关键词、浏览历史等与商品描述进行深度语义匹配,为用户推荐更符合其需求和兴趣的商品,提高推荐的准确性和用户满意度。
内容推荐:在视频、音乐等内容推荐平台中,交叉编码器检索器能够理解用户的偏好和内容的语义特征,实现更精准的内容推荐,帮助用户发现感兴趣的视频、音乐等内容。