VGG Image Annotator (VIA)用于图像、视频和音频数据的标注,支持多种标注类型,如区域标注、关键点标注等,并且可以将标注结果以JSON等格式导出,方便与各种机器学习框架集成,具有良好的跨平台性和可扩展性。
VIA由牛津大学的视觉几何组(VGG)开发。使用JavaScript、HTML和CSS实现。
基于网页的轻量级注释工具,无需安装或设置,可在大多数现代浏览器中作为离线应用程序运行,核心功能在一个小于400KB的HTML页面中实现。
项目地址:https://gitlab.com/vgg/via
一、功能特点
1.标注类型
图像注释:可进行框选、点选、多边形绘制等注释操作。
音频注释:支持对音频文件进行时间轴标记和注释。
视频注释:能对视频文件进行帧级注释和时间轴标记。
2.数据导出:注释结果可导出为JSON、XML、CSV等多种格式,便于与其他软件集成,满足不同后续处理需求。
3.操作界面:具有直观的交互界面,提供各种形状工具,如矩形、圆形等,方便用户进行标注操作,还可添加标签和属性描述,新手也能快速上手。
4.支持自定义:允许用户自定义标签和注释,可根据特定的标注任务和需求,灵活设置标注类别、属性等,提高标注的准确性和针对性。
二、图像标注
VIA支持多种类型的图像标注:
1.边界框标注:用户可以在图像上绘制矩形边界框,用于标注图像中的特定目标物体,比如在一张包含汽车的图片中,使用边界框标注出汽车的位置和大致范围,常用于物体检测任务,帮助模型识别和定位图像中的不同物体。
2.点标注:能够在图像上标记出特定的点,例如在医学影像中标记出肿瘤的中心点,或者在人脸图像上标记出五官的关键点等,对于需要精确确定特定位置的任务非常有用,如人脸特征点识别、地理坐标标注等。
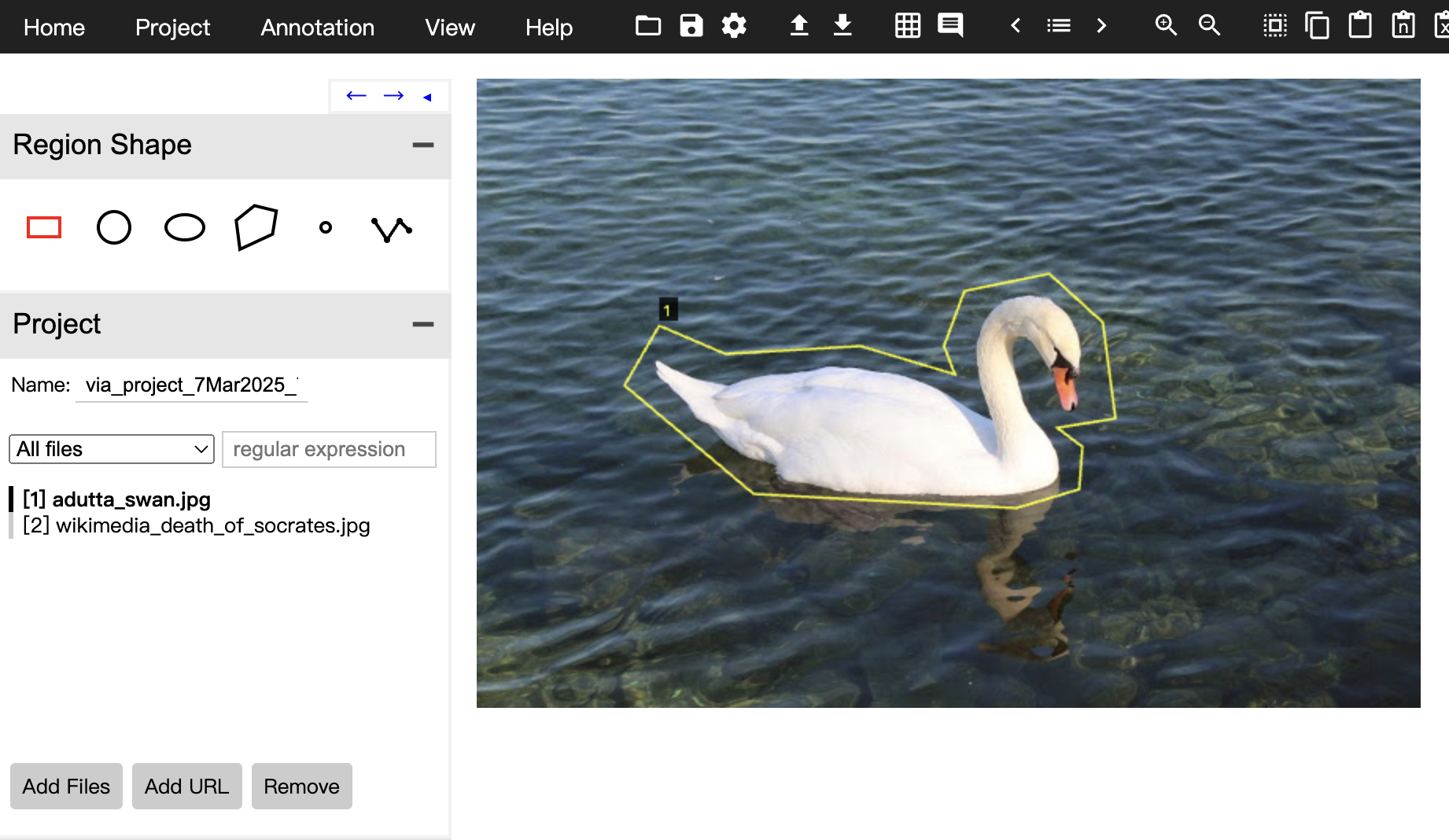
3.多边形标注:可以通过绘制多边形来精确地勾勒出图像中目标物体的轮廓,适用于标注形状不规则的物体,比如在标注自然场景中的湖泊、森林边界,或者医学图像中的病变区域等,能更准确地描述目标物体的形状和范围。
4.圆形标注:用于在图像上标注出圆形区域,比如在标注细胞图像中的细胞时,如果细胞近似圆形,就可以使用圆形标注来圈定细胞,在一些需要关注圆形物体或区域的场景中较为常用,如天体图像中的星球、工业检测中的圆形零件等。
5.折线标注:能够绘制折线来标注图像中的特定线条或路径,例如在标注道路图像中的车道线、电路图中的线路等,可用于需要描述线条或路径信息的任务,帮助模型学习和理解图像中的线性特征。
6.语义分割标注:可以对图像中的不同区域进行不同类别的标注,将图像中的每个像素都划分到特定的类别中,实现对图像的语义分割,比如将一幅自然场景图像中的天空、草地、树木等不同元素分别标注为不同的类别,用于语义分割任务的数据集标注。
三、音频标注
1.时间轴标记:用户可以在音频的时间轴上标记出特定的时间点或时间段,比如在一段语音中标记出某个关键词出现的时间,或者在一段音乐中标记出不同乐章、旋律段落的起止时间等,便于对音频内容进行时间维度上的定位和分析。
2.事件标注:能够对音频中发生的特定事件进行标注,例如在一段环境音中标记出车辆行驶声、鸟鸣声、人声等不同声音事件的出现时刻和持续时间,有助于对音频中的声音元素进行分类和识别。
3.情感标注:根据音频的语调、节奏、音色等特征,对音频所表达的情感状态进行标注,如积极、消极、平静、兴奋等,可应用于情感分析相关的研究和任务中。
4.语音内容标注:将语音转写为文本形式,同时可以对语音中的特定内容、主题等进行标注,比如在会议录音中标记出不同发言人的讲话内容、讨论的议题等,方便后续的语音检索和内容分析。
四、视频标注
1.帧级标注
物体检测标注:在视频的每一帧中,使用边界框等方式标注出目标物体的位置和类别,例如在交通监控视频中标记出车辆、行人、交通标志等物体,为视频中的目标检测任务提供数据支持。
关键点标注:在视频帧中的特定物体上标记出关键点,如在人体动作分析视频中标记出人体的关节点,用于分析人体的动作姿态和运动轨迹。
语义分割标注:对视频帧中的每个像素进行分类标注,将不同的物体或场景区域划分到不同的类别中,比如区分视频中的天空、地面、建筑物、树木等,可用于视频语义理解和场景分析。
2.时间轴标记
动作识别标注:在视频的时间轴上标记出特定动作或行为的起止时间,如在体育比赛视频中标记出运动员的投篮、传球、射门等动作的发生时间段,用于动作识别和行为分析。
事件标注:标注视频中发生的特定事件的时间范围,例如在新闻视频中标记出采访、突发事件、重要讲话等事件的出现时间,便于视频内容的索引和检索。
视频段落标注:根据视频的内容结构,将视频划分为不同的段落,并对每个段落进行标注,如在电影视频中标记出不同的剧情章节、在教学视频中标记出不同的知识点讲解段落等,有助于视频内容的组织和管理。
五、使用方式
1.安装启动:确保系统安装了Python环境,克隆项目到本地,通过pip安装所需依赖项,运行python app.py启动本地服务器,默认访问地址是http://localhost:8000/。
2.具体操作
上传图片:点击“Add files”按钮上传要标注的图片。
创建项目:选择图片后,可通过右侧面板设置新的项目或选择现有项目继续工作。
进行标注:利用工具栏上的形状工具拖动鼠标完成标注,并添加标签和属性描述。
保存数据:完成标注后,通过“Export annotations”导出CSV或者JSON格式的数据。
六、应用场景
用于标注物体检测和分类任务的数据集,为模型训练提供基础数据。帮助研究人员标注病变区域,辅助医学诊断和研究。
1.工业制造领域
齿轮缺陷检测:在对齿轮图像数据中的缺陷进行标注时,采用VIA图像标注工具对齿轮数据集缺陷进行人工标注。将齿轮端面和齿面的倒角有无、黑皮齿底、黑皮齿面、磕碰等四种缺陷类型分别命名为相应标签,在VIA中将图像数据导入工具内进行标注,可得到记载缺陷坐标信息和缺陷类型的via_project.json工程文件,后续可将其转化为yolo格式的图像标签用于模型训练。
电路板检测:在电路板生产过程中,需要检测电路板上的电子元件是否焊接正确、是否存在短路等问题。使用VIA对电路板图像进行标注,标记出存在问题的区域和类型,如虚焊、短路、元件缺失等,为后续的缺陷检测模型训练提供数据支持。
2.医疗领域
抗原检测模型训练:在使用Mask RCNN训练抗原检测模型时,收集了抗原检测图,利用VIA对图片中的抗原边界进行单独标记,标记完导出json文件,放到训练和验证目录下,用于后续的模型训练,以实现对抗原试剂的识别。
医学影像分析:在肺部疾病诊断中,医生可以使用VIA对肺部CT影像进行标注,标记出肺部结节、炎症区域等病变部位,为计算机辅助诊断系统提供标注数据,帮助开发能够自动识别和分析肺部疾病的人工智能模型。
3.安防领域
安全帽佩戴检测:在利用图像识别技术进行安全帽佩戴检测时,需要大量的带标注图像数据来训练模型。通过VIA可以对采集到的施工现场图像进行标注,标记出人员是否佩戴安全帽以及安全帽的位置等信息,为基于深度学习的安全帽佩戴检测算法提供训练数据。
人脸识别系统:在构建人脸识别系统时,使用VIA对人脸图像进行标注,标记出人脸的关键特征点,如眼睛、鼻子、嘴巴等位置,用于训练人脸识别算法,提高算法对人脸特征的提取和识别能力。
4.农业领域
农作物病虫害检测:对农作物的叶片图像进行采集后,使用VIA标注工具标记出叶片上的病虫害区域,标注出病虫害的类型、严重程度等信息,为农作物病虫害检测模型提供数据,以便实现对农作物病虫害的快速检测和诊断。
果实采摘机器人:为了让果实采摘机器人能够准确识别果实的位置和成熟度,利用VIA对果园中的果实图像进行标注,标记出果实的位置、大小、颜色等特征,以及果实是否成熟等信息,用于训练果实采摘机器人的视觉识别模型。